Por tratar-se de uma nova ameaça, sabe-se muito pouco sobre o coronavírus (Sars-CoV-2). Esse fator dá grande abertura para disseminação de fake news (como ficou popularmente conhecido o compartilhamento de informações falsas), que podem ir desde supostos métodos de prevenção, tratamentos caseiros, cura do vírus e até mesmo tratamentos controversos recomendados por médicos, mesmo que não haja comprovação ou evidência científica para tais. Tudo isso pode dificultar o trabalho de órgãos de saúde, prejudicar a adoção de medidas de distanciamento social pela população e acarretar aumentos dos números de infectados e de morte pelo vírus.
Para diminuir os impactos dessa desinformação, diversos sites de checagem de fatos têm ferramentas que identificam e classificam (manualmente) tais notícias. Em geral, essas ferramentas poderiam fazer uso de algoritmos de aprendizagem de máquina para classificação de notícias. Diante dessa problemática, é evidente a necessidade de elaborar mecanismos e ferramentas que possam combater eficientemente o caos das fakes news.
Por isso, durante as disciplinas de Aprendizagem de Máquina e Mineração de Dados (Programa de Pós-graduação em Ciência da Computação da Universidade Federal do Ceará (MDCC-UFC)), nós (Andreza Fernandes, Felipe Marcel, Flávio Carneiro e Marianna Ferreira) propusemos um detector de fake news para analisar notícias sobre o COVID-19 divulgadas em redes sociais. Nosso objetivo é ajudar a população quanto ao esclarecimento da veracidade dessas informações.
Agora, detalharemos o processo de desenvolvimento desse detector de fake news.
Objetivos do projeto
- Formar uma base dados de textos com notícias falsas e verdadeiras acerca do COVID-19;
- Diminuir enviesamento das notícias;
- Experimentar diferentes representações textuais;
- Experimentar diferentes abordagens clássicas de aprendizagem de máquina e deep learning;
- Construir um BOT no Telegram que ajude na detecção de notícias falsas relacionadas ao COVID-19.
Entendendo as terminologias usadas
Para o entendimento dos experimentos realizadas, vamos conceituar alguns pontos chaves e técnicas de Processamento de Linguagem Natural.
Tokenização: Esse processo transforma todas as palavras de um texto, dado como entrada, em elementos (conhecidos como tokens) de um vetor.
Remoção de Stopwords: Consiste na remoção de palavras de parada, como “a”, “de”, “o”, “da”, “que”, “e”, “do”, dentre outras, pois na maioria das vezes não são informações relevantes para a construção do modelo.
Bag of words: É uma representação simplificada e esparsa dos dados textuais. Consiste em gerar uma bolsa de palavras do vocabulário existente no dado, que constituirá as features do dataset. Para cada sentença é assinalado um “1” nas colunas que apresentam as palavras que ocorrem na sentença e “0” nas demais.
Term Frequency – Inverse Document Frequency (TF-IDF): Indica a importância de uma palavra em um documento. Enquanto TF está relacionada à frequência do termo, IDF busca balancear a frequência de termos mais comuns/frequentes que outros.
Word embeddings: É uma forma utilizada para representar textos, onde palavras que possuem o mesmo sentido têm uma representação muito parecida. Essa técnica aprende automaticamente, a partir de um corpus de dados, a correlação entre as palavras e o contexto, possibilitando que palavras que frequentemente ocorrem em contextos similares possuam uma representação vetorial próxima. Essa representação possui a vantagem de ter um grande poder de generalização e apresentar baixo custo computacional, uma vez que utiliza representações densas e com poucas dimensões, em oposição a técnicas esparsas, como Bag of Words. Para gerar o mapeamento entre dados textuais e os vetores densos mencionados, existem diversos algoritmos disponíveis, como Word2Vec e FastText, os quais são utilizados neste trabalho.
Out-of-vocabulary (OOV): Consiste nas palavras presentes no dataset que não estão presentes no vocabulário da word embedding, logo, elas não possuem representação vetorial.
Edit Distance: Métrica que quantifica a diferença entre duas palavras, contando o número mínimo de operações necessárias para transformar uma palavra na outra.
Metodologia
Agora iremos descrever os passos necessários para a obtenção dos resultados, geração dos modelos e escolha daquele com melhor performance para a efetivação do nosso objetivo.
Obtenção dos Dados
Os dados utilizados para a elaboração dos modelos foram adquiridos das notícias falsas brasileiras sobre o COVID-19, dispostos no Chequeado, e de um web crawler dos links das notícias, utilizadas para comprovar que a notícia é falsa no Chequeado, para formar uma base de notícias verdadeiras. Além disso também foi realizado um web crawler para obtenção de notícias do Fato Ou Fake do G1.
Originalmente, os dados obtidos do Chequeado possuíam as classificações “Falso”, “Enganoso”, “Parcialmente falso”, “Dúbio”, “Distorcido”, “Exagerado” e “Verdadeiro mas”, que foram mapeadas todas para “Falso”. Com isso, transformamos nosso problema em classificação binária.
No final, obtivemos um dataset com 1.753 notícias, sendo 808 fakes, simbolizada como classe 0, e 945 verdadeiras, classe 1, com um vocabulário de tamanho 3.698. Com isso, dividimos o nosso dado em conjunto de treino e teste, com tamanhos de 80% e 20%, respectivamente.
Pré-processamento
Diminuição do viés. Ao trabalhar e visualizar os dados, notamos que algumas notícias verdadeiras vinham com palavras e sentenças que enviesavam e deixavam bastante claro para os algoritmos o que é fake e o que é verdadeiro, como: “É falso que”, “#Checamos”, “Verificamos que” e etc. Com isso, removemos essas sentenças e palavras, a fim de diminuir o enviesamento das notícias.
Limpeza textual. Após a etapa anterior, realizamos a limpeza do texto, consistindo em remoção de caracteres estranhos e sinais de pontuação e uso do texto em caixa baixa.
Tokenização. A partir do texto limpo, inicializamos o processo de tokenização das sentenças.
Remoção das Stopwords. A partir das sentenças tokenizadas, removemos as stopwords.
Representação textual
Análise exploratória
A partir do pré-processamento dos dados brutos, inicializamos o processo de análise exploratória dos dados. Verificamos o tamanho do vocabulário do nosso dataset, que totaliza 3.698 palavras.
Análise do Out-of-vocabulary. Com isso, verificamos o tamanho do nosso out-of-vocabulary em relação às word embeddings pré-treinadas utilizadas, totalizando 32 palavras. Um fato curioso é que palavras chaves do nosso contexto encontram-se no out-of-vocabulary e acabam sendo mapeadas para palavras que não tem muita conexão com o seu significado. Abaixo é possível ver algumas dessas palavras mais à esquerda, e a palavra a qual foram mapeadas mais à direita.


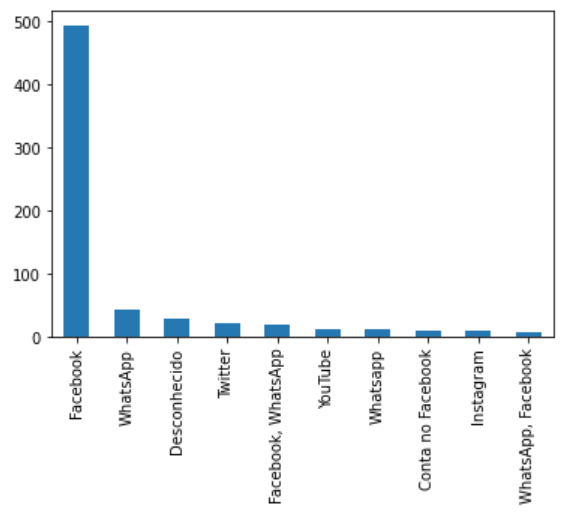
Análise da frequência das fake news por rede social. O dado bruto original advindo do Chequeado possui uma coluna que diz sobre a mídia social em que a fake news foi divulgada. Após uma análise visual superficial, apenas plotando a contagem dos valores dessa coluna (que acarreta até na repetição de redes sociais), notamos que os maiores veículos de propagação de fake news são o Facebook e Whatsapp.

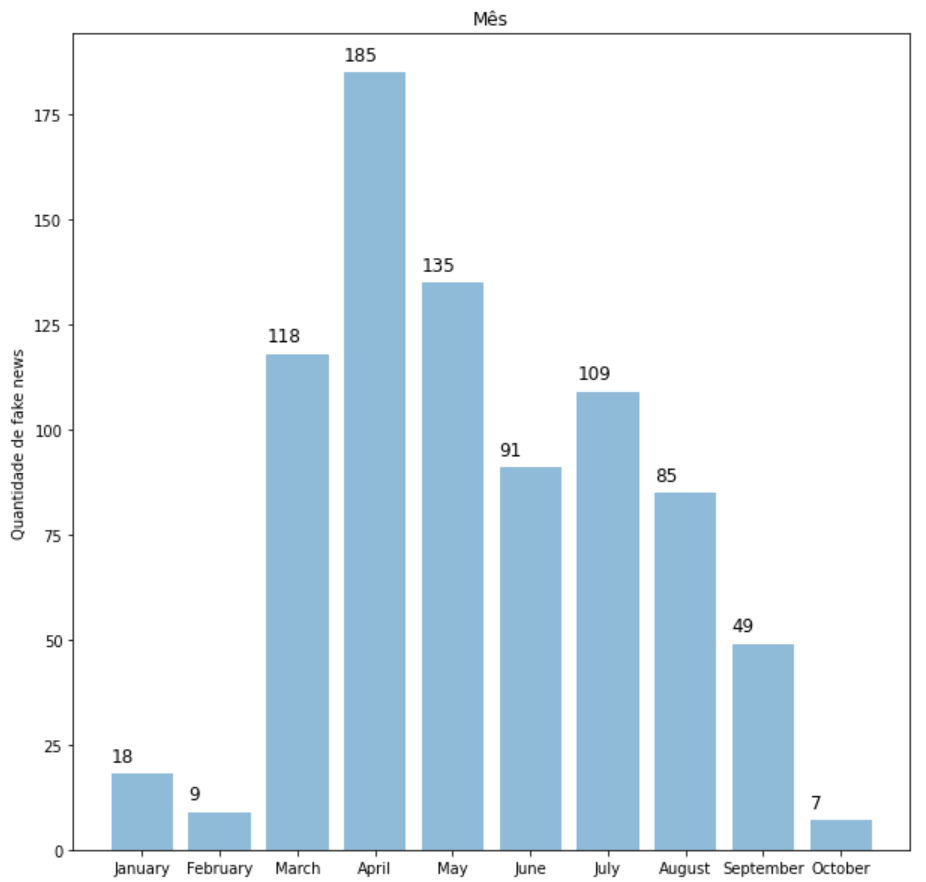
Análise da quantidade de fake news ao longo dos meses. O dado bruto original advindo do Chequeado também possui uma coluna que informava a data de publicação da fake news. Após realizar uma análise visual da distribuição da quantidade de fake news ao longo dos meses, notamos que o maior número de fake news ocorreu em abril, mês em que a doença começou a se espalhar com maior velocidade no território brasileiro. De acordo com o G1, em 28 de abril, o Brasil possuía 73.235 casos do novo coronavírus (Sars-CoV-2), com 5.083 mortes. Além disso, foi nesse mês que começaram a surgir os boatos de combate do Coronavírus via Cloroquina, além de remédios caseiros.

Análise da Word Cloud. Com as sentenças tokenizadas, também realizamos uma visualização usando a técnica de Word Cloud, que apresenta as palavras do vocabulário em um tamanho proporcional ao seu número de ocorrência no todo. Com essa técnica, realizamos duas visualizações, uma para as notícias verdadeiras e outra para as fake news.




Divisão treino e teste
A divisão dos conjuntos de dados entre treino e teste foi feita com uma distribuição de 80% e 20% dos dados, respectivamente. Os dados de treino foram ainda divididos em um novo conjunto de treino e um de validação, com uma distribuição de 80% e 20% respectivamente.
Aplicação dos modelos
Para gerar os modelos, escolhemos algoritmos e técnicas clássicas de aprendizagem de máquina, tais como técnicas atuais e bastante utilizadas em competições, sendo eles:
- Regressão Logística (*): exemplo de classificador linear;
- K-NN (*): exemplo de modelo não-paramétrico;
- Análise Discriminante Gaussiano (*): exemplo de modelo que não possui hiperparâmetros;
- Árvore de Decisão: exemplo de modelo que utiliza abordagem da heurística gulosa;
- Random Forest: exemplo de ensemble de bagging de Árvores de Decisão;
- SVM: exemplo de modelo que encontra um ótimo global;
- XGBoost: também um ensemble amplamente utilizado em competições do Kaggle;
- LSTM-Dense: exemplo de arquitetura que utiliza deep learning.
Os algoritmos foram utilizados por meio de implementações próprias (aqueles demarcados com *) e uso da biblioteca scikit-learn e keras. Para todos os algoritmos, com exceção daqueles que não possuem hiperparâmetros e LSTM-Dense, realizamos Grid Search em busca dos melhores hiperparâmetros e realizamos técnicas de Cross Validation para aqueles utilizados por meio do Scikit-Learn, com k fold igual a 5.
Obtenção das métricas
As métricas utilizadas para medir a performance dos modelos foram acurácia, Precision, Recall, F1-score e ROC.
Tabela 1. Resultados das melhores representações por algoritmo
| MODELOS | PRECISION | RECALL | F1-SCORE | ACCURACY | ROC |
| XGBoost BOW e TF-IDF* | 1 | 1 | 1 | 1 | 1 |
| SVM BOW E TF-IDF* | 1 | 1 | 1 | 1 | 1 |
| Regressão Logística BOW | 0.7560 | 0.7549 | 0.7539 | 0.7549 | 0.7521 |
| LSTM FASTTEXT | 0.7496 | 0.7492 | 0.7493 | 0.7492 | 0.7492 |
| Random Forest TF-IDF | 0.7407 | 0.7407 | 0.7402 | 0.7407 | 0.7388 |
| Árvore de Decisão TF-IDF | 0.7120 | 0.7122 | 0.7121 | 0.7122 | 0.7111 |
| Análise Discriminante Gaussiano Word2Vec | 0.7132 | 0.7122 | 0.7106 | 0.7122 | 0.7089 |
| k-NN FastText | 0.6831 | 0.6809 | 0.6775 | 0.6638 | 0.6550 |
Tabela 2. Resultados das piores representações por algoritmo
| MODELOS | PRECISION | RECALL | F1-SCORE | ACCURACY | ROC |
| XGBoost Word2Vec | 0.7238 | 0.7236 | 0.7227 | 0.7236 | 0.7211 |
| SVM Word2Vec | 0.7211 | 0.7179 | 0.7151 | 0.7179 | 0.7135 |
| Árvore de Decisão Word2Vec | 0.6391 | 0.6353 | 0.6351 | 0.6353 | 0.6372 |
| Random Forest Word2Vec | 0.6231 | 0.6210 | 0.6212 | 0.6210 | 0.62198 |
| Regressão Logística FastText | 0.6158 | 0.5982 | 0.5688 | 0.59829 | 0.5858 |
| Análise Discriminante Gaussiano TF-IDF | 0.5802 | 0.5811 | 0.5801 | 0.5811 | 0.5786 |
| k-NN BOW | 0.5140 | 0.5099 | 0.5087 | 0.5042 | 0.5127 |
| LSTM WORD2VEC (*) | 0.4660 | 0.4615 | 0.4367 | 0.4615 | 0.4717 |
Resultados
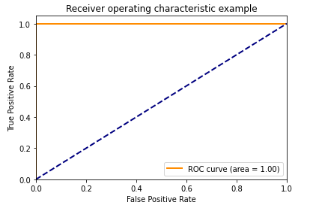
Com os resultados apresentados percebemos que os modelos SVM e XGBoost com as representações TF-IDF e BOW atingiram as métricas igual a 100%. Isso pode ser um grande indicativo de sobreajuste do modelo aos dados. Abaixo podemos visualizar a matriz de confusão e a curva ROC dos mesmos.

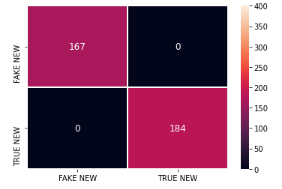

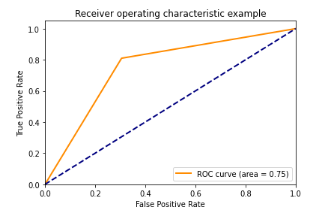
Logo após vem a Regressão Logística com métricas em torno de ~75.49%! Abaixo podemos visualizar sua matriz de confusão e a curva ROC.



Exemplos de classificações da Regressão Logística
- True Positive (corretamente classificada)
- Texto que diz que vitamina C e limão combatem o coronavírus
- True Negative (corretamente classificada)
- Notícia divulgada em 2015 pela TV italiana RAI comprova que o novo coronavírus foi criado em laboratório pelo governo chinês.
- False Positive (erroneamente classificada)
- Vitamina C com zinco previne e trata a infecção por coronavírus
- False Negative (erroneamente classificada)
- Que neurocientista britânico publicou estudo mostrando que 80% da população é imune ao novo coronavírus
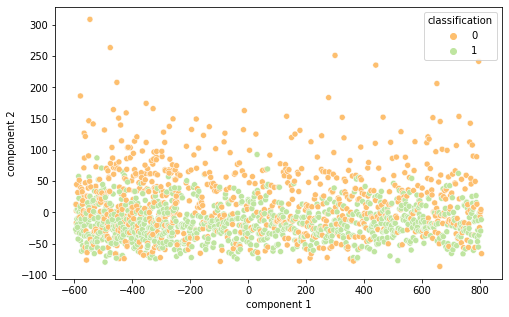
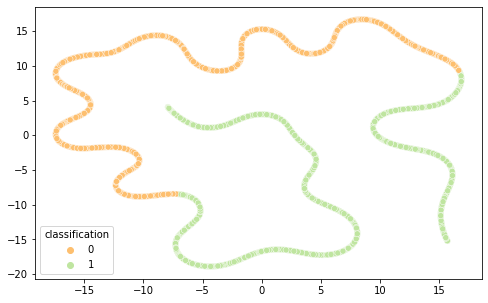
Intrigados com os resultados, resolvemos visualizar as diferentes representações de dados em 2 componentes principais (visto a alta dimensionalidade do dado, o que prejudica a análise do que está acontecendo de fato) por meio das técnicas de PCA e T-SNE, separando por cor de acordo com sua classificação.
É interessante notar que as representações de word embeddings utilizadas possui uma representação bastante confusa e misturada. Já as representações TF-IDF e Bag of Words são facilmente separáveis.


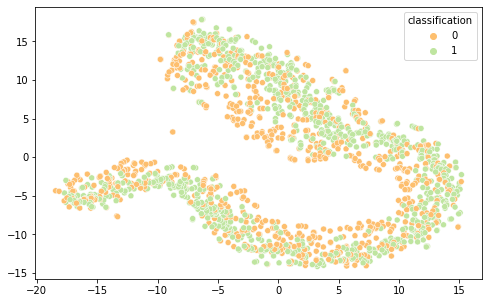


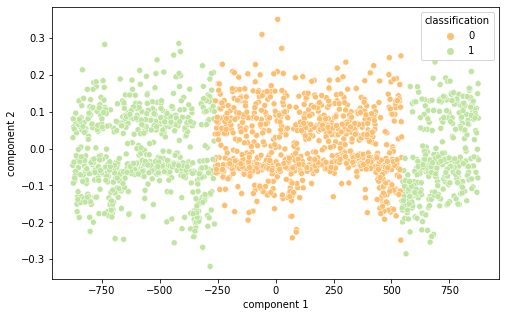
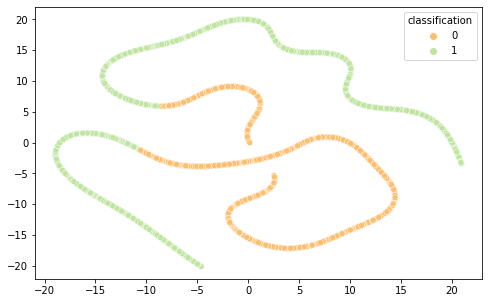
BOW T-SNE
Conclusão
A base de dados utilizada para obtenção dos modelos foi obtida por meio do site Chequeado, e, posteriormente, houve o enriquecimento dessa base por meio do web crawler, totalizando 1.383 registros, sendo 701 fake news e 682 notícias verdadeiras.
Para representação textual foram utilizadas as técnicas Bag of Words, TF-IDF e Word embeddings Word2Vec e FastText de 300 dimensões com pesos pré-treinados obtidas por meio da técnica CBOW com dimensões, disponibilizadas pelo Núcleo Interinstitucional de Linguística Computacional (NILC). Para gerar os modelos foram utilizados os algoritmos Regressão Logística, kNN, Análise Discriminante Gaussiano, Árvore de Decisão, Random Forest, Gradient Boosting, SVM e LSTM-Dense. Para avaliação dos modelos foi utilizado as métricas Acurácia, Precision, Recall, F1-score, AUC-ROC e matriz de confusão.
Considerando os experimentos e os resultados, conclui-se que o objetivo principal deste trabalho, gerar modelos capazes de classificar notícias extraídas de redes sociais relacionadas ao COVID-19 como falsas e verdadeiras, foi alcançado com êxito. Como resultados, vimos que os modelos SVM e XGBoost com TF-IDF e BOW atingiram 100% nas métricas, com grandes chances de terem se sobreajustado aos dados. Com isso, consideramos como melhor modelo a Regressão Logística com a representação BOW, atingindo as métricas com valores próximos a 75.49%.
O pior classificador foi o kNN com o BOW e LSTM-Dense com Word2Vec, porém é importante ressaltar que este último não contou com Grid Search e foi treinado com poucas épocas. No geral, as melhores representações foram a TF-IDF e BOW e a pior o Word2Vec.
Para este projeto houveram algumas dificuldades, sendo a principal delas a formação da base de dados, visto que o contexto pandêmico do COVID-19 é algo novo e devido à limitação da API do Twitter em relação ao tempo para extrair os tweets, que era originalmente a ideia da base de dados para esse projeto. Além disso, também houve a dificuldade de remoção do viés dos dados.
Como trabalhos futuros, visamos:
- Ampliar a base de dados;
- Investigar o que levou ao desempenho do SVM, XGBOOST com as representações TF-IDF e BOW.
- Analisar performance dos modelos utilizando outras word embeddings pré-treinadas, como o BERT, Glove e Wang2vec.
- Investigar o uso do modelo pré-treinado do BERT e com fine-tuned.
- Aplicar PCA Probabilístico
- Utilizar arquiteturas de deep learning mais difundidas na comunidade científica.