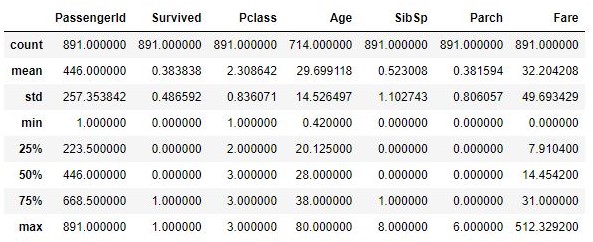
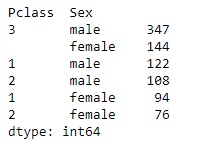
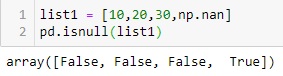
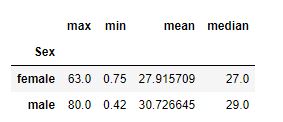
Quando a Copa do Mundo começa, bilhões de olhos se voltam para os gramados. Torcedores fazem suas apostas, comentaristas apontam favoritos e especialistas analisam elencos, táticas e retrospectos.
Mas existe outra competição acontecendo fora dos estádios. Em universidades, centros de pesquisa, empresas de análise de dados e até bancos de investimento, cientistas, estatísticos e especialistas em inteligência artificial travam uma disputa silenciosa: desenvolver modelos capazes de prever o desempenho das seleções e estimar quem tem mais chances de levantar a taça.
A pergunta parece simples: É possível usar ciência de dados para prever o campeão da Copa do Mundo?
A resposta é muito mais interessante do que um simples “sim” ou “não” e nos leva a uma fascinante combinação de estatística, aprendizado de máquina, simulações computacionais e teoria das probabilidades.
Quando a ciência entrou em campo
A ideia de prever resultados esportivos não é nova. Há décadas, pesquisadores utilizam métodos estatísticos para analisar o desempenho de equipes e estimar resultados futuros. Nas últimas décadas, porém, a quantidade de dados disponíveis transformou completamente esse cenário.
Hoje, cada partida produz uma enorme quantidade de informações: posse de bola, finalizações, passes, desempenho individual dos atletas, histórico de confrontos, rankings internacionais e indicadores de desempenho físico e técnico.
Com esse volume de dados, cientistas passaram a desenvolver modelos capazes de estimar a força relativa de cada seleção e calcular probabilidades para os diferentes cenários de um torneio.
O objetivo não é adivinhar o futuro. É algo mais sofisticado: medir a probabilidade de que determinados eventos aconteçam.
Nessa imensidão de dados, a Copa do Mundo passou a ser vista também como um grande laboratório para cientistas de dados.
Entre os grupos mais conhecidos nessa área estão pesquisadores da TU Dortmund University, na Alemanha, e da University of Innsbruck, na Áustria. Há anos, esses pesquisadores desenvolvem modelos estatísticos para prever resultados de grandes competições internacionais, combinando estatística clássica, aprendizado de máquina e simulações computacionais.


Mas as universidades não estão sozinhas. Instituições financeiras como o Goldman Sachs também publicam previsões para a Copa do Mundo, utilizando modelos próprios baseados em rankings e probabilidades. Para a Copa de 2026, por exemplo, o banco utilizou uma versão aprimorada do sistema Elo para calcular as chances de cada seleção conquistar o título.
Durante muitos anos, outro protagonista importante foi o site esportivo FiveThirtyEight, que se tornou referência mundial por suas previsões baseadas em dados para eleições, esportes e eventos diversos. Seus modelos para Copas do Mundo ficaram conhecidos pela transparência metodológica e pela riqueza das análises apresentadas ao público.
O que exatamente esses modelos tentam prever?
Ao contrário do que muita gente imagina, os pesquisadores não tentam responder apenas à pergunta “quem será campeão?”. Na verdade, essa é apenas uma das dezenas de previsões produzidas pelos modelos.
Antes mesmo do início da competição, é comum que eles estimem:
- Probabilidade de classificação na fase de grupos;
- Probabilidade de chegar às oitavas de final;
- Probabilidade de alcançar as quartas;
- Probabilidade de disputar as semifinais;
- Probabilidade de chegar à final;
- Probabilidade de conquistar o título.
Alguns pesquisadores vão além. Modelos estatísticos também já foram utilizados para analisar a justiça dos sistemas de classificação para a Copa do Mundo, calcular probabilidades de qualificação de seleções e avaliar o impacto de mudanças no formato do torneio. Ou seja, a ciência de dados não se limita a prever resultados. Ela também ajuda a compreender a própria estrutura das competições.
O ranking que nasceu no xadrez e conquistou o futebol
Uma das ferramentas mais importantes na previsão esportiva surgiu com o xadrez.
Na década de 1960, o físico e enxadrista americano Arpad Elo desenvolveu um método para medir a força relativa dos jogadores. A lógica era simples. Se um jogador forte derrota um adversário fraco, o resultado era esperado e gera poucos ajustes na pontuação. Mas, quando um jogador considerado inferior vence um favorito, a pontuação sofre uma mudança significativa.
Com o tempo, essa ideia foi adaptada para diversas modalidades esportivas, incluindo o futebol.
Hoje, o sistema Elo é um dos pilares de inúmeros modelos de previsão da Copa do Mundo. Ele permite estimar a força relativa das seleções com base em seus resultados recentes, considerando também a qualidade dos adversários enfrentados.
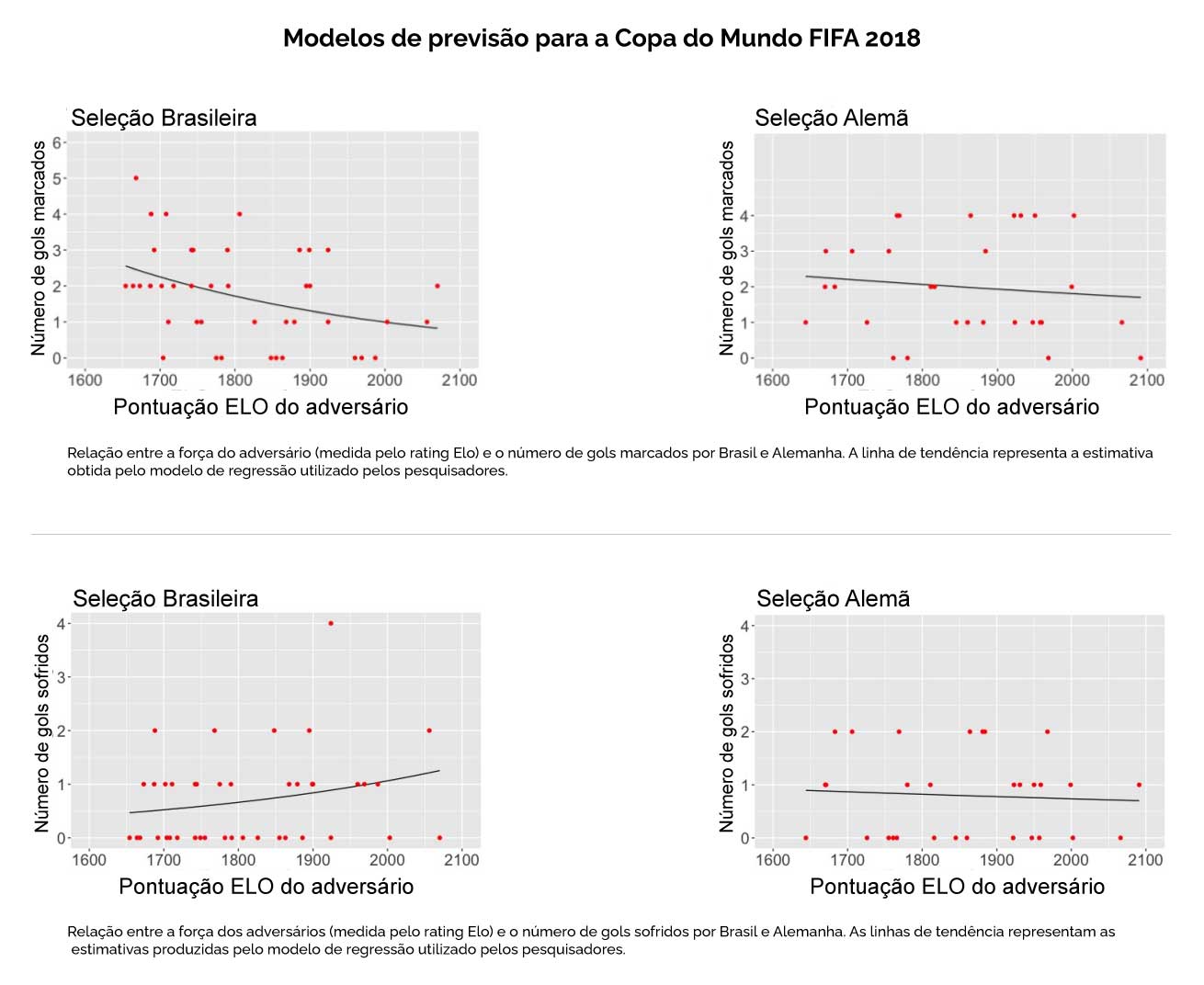
Um exemplo pode ser visto na imagem abaixo. Nela, pesquisadores analisaram partidas de Brasil e Alemanha antes da Copa de 2018 para verificar como a força dos adversários, medida pelo sistema Elo, se relacionava com o número de gols marcados e sofridos. Nos gráficos superiores, cada ponto representa uma partida e mostra a relação entre o rating Elo do adversário e os gols marcados pela seleção. Nos gráficos inferiores, a mesma análise é feita para os gols sofridos. As linhas pretas indicam a tendência estimada pelo modelo estatístico. De forma geral, observa-se que, à medida que a qualidade do adversário aumenta, o número de gols marcados tende a diminuir, enquanto a quantidade de gols sofridos pode aumentar. Esse tipo de relação ajuda os modelos a estimar o desempenho esperado de uma seleção diante de diferentes oponentes.

O sistema Elo atribui uma pontuação para cada equipe com base em seus resultados anteriores. Vencer uma seleção forte gera mais pontos do que vencer uma seleção considerada mais fraca.
Esse método não serve apenas para classificar seleções. Ele também fornece informações que ajudam os modelos a estimar quantos gols uma equipe tende a marcar ou sofrer contra adversários de diferentes níveis.
Ao longo do tempo, esse mecanismo produz uma estimativa bastante consistente da força relativa de cada seleção.
Quando a estatística encontra a inteligência artificial
O Elo é apenas o ponto de partida. Os modelos mais modernos combinam diferentes técnicas estatísticas e de aprendizado de máquina.
Em um estudo desenvolvido para a Copa de 2018, pesquisadores liderados por Andreas Groll compararam diversas abordagens, incluindo regressões estatísticas, métodos de ranking e algoritmos de Random Forest. O resultado mostrou que a combinação de diferentes técnicas produzia previsões mais precisas do que qualquer método isolado.
Mais recentemente, pesquisadores desenvolveram modelos híbridos que combinam:
- Modelos lineares generalizados;
- Random Forest;
- Extreme Gradient Boosting (XGBoost);
- Rankings de seleções;
- Dados históricos de partidas;
- Avaliações individuais de jogadores.
Essa combinação ilustra uma tendência cada vez mais comum na ciência de dados; em vez de buscar um único algoritmo perfeito, os pesquisadores combinam diferentes modelos para aproveitar os pontos fortes de cada abordagem.
A técnica que simula milhares de Copas do Mundo
Imagine que você pudesse assistir à mesma Copa do Mundo cem mil vezes.
Em algumas versões, o Brasil seria eliminado precocemente 😫. Outros cenários mostrariam o país chegando à final. Certas simulações resultariam em uma seleção considerada favorita conquistando o título. Em outras, ocorreria uma zebra histórica.
É exatamente isso que os computadores fazem. Depois de estimar as probabilidades de cada partida, os pesquisadores utilizam um método conhecido como Simulação de Monte Carlo.
Nesse processo, o torneio inteiro é reproduzido milhares, ou até centenas de milhares, de vezes virtualmente. Ao repetir esse processo milhares de vezes, o modelo calcula com que frequência cada cenário ocorre. O resultado não é um único campeão previsto, mas uma distribuição de probabilidades.
Os resultados dessas simulações permitem calcular a frequência com que cada cenário acontece. Por exemplo: se uma seleção vencer 18 mil vezes em um conjunto de 100 mil simulações, seu modelo atribuirá aproximadamente 18% de chance de título.

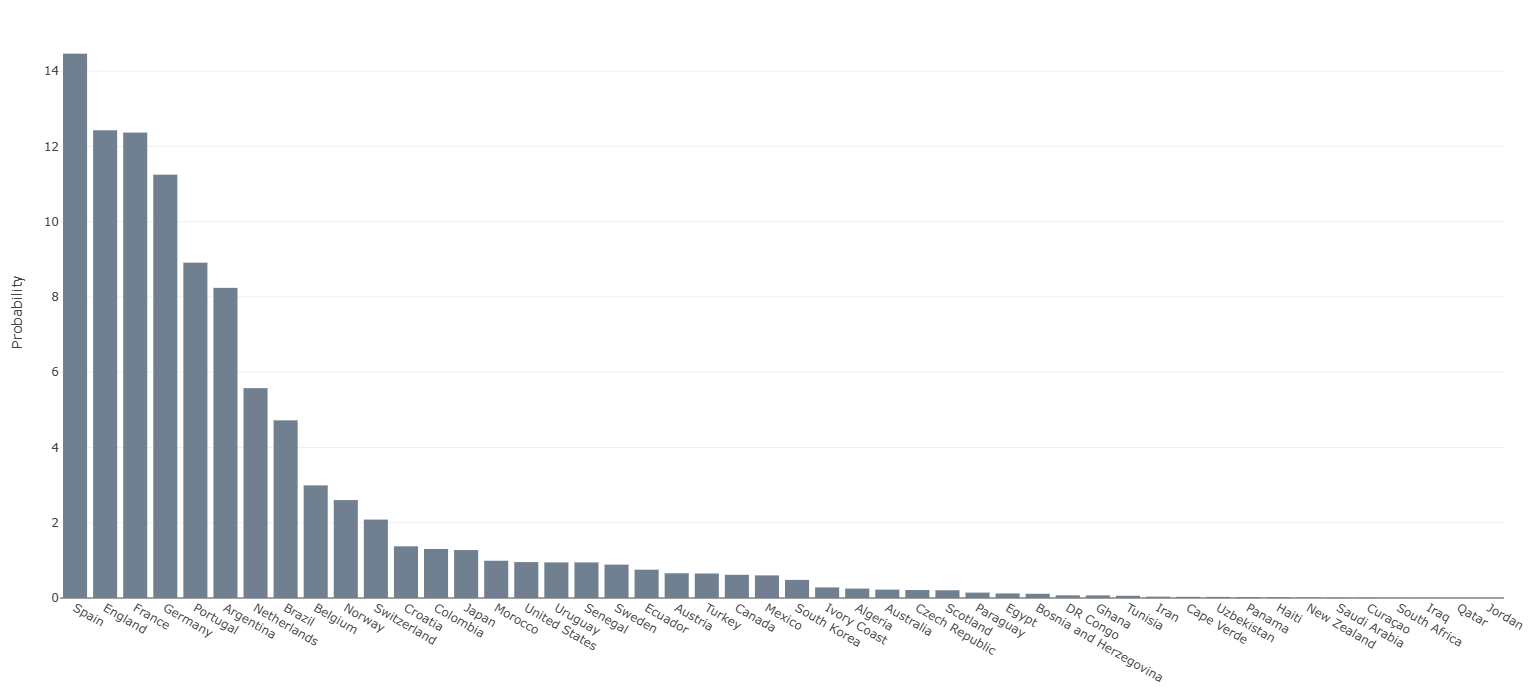
Perceba algo importante. Mesmo a seleção favorita costuma ter probabilidades relativamente baixas.
E isso nos leva a uma das principais lições da ciência de dados.
O maior erro de interpretação sobre previsões
Quando uma previsão aponta uma seleção com 18% de chance de ser campeã, muitas pessoas interpretam isso como:
“O modelo está dizendo que ela será campeã.”
Mas não é isso que significa. Na verdade, o modelo está afirmando justamente o contrário. Ele está dizendo que existe 82% de chance de outro cenário acontecer.
A ciência de dados não trabalha com certezas. Ela trabalha com probabilidades.
Por isso, os pesquisadores frequentemente alertam que o objetivo dos modelos não é eliminar a incerteza, mas quantificá-la.
O estatístico Andreas Groll, um dos pesquisadores mais conhecidos nessa área, costuma destacar que até mesmo os favoritos raramente ultrapassam a marca de 20% de probabilidade de título em torneios internacionais.
Isso ajuda a explicar por que o futebol continua sendo tão difícil de prever.
Quando os modelos acertam…
Ao longo dos anos, diversos sistemas de previsão ganharam notoriedade por apontar corretamente algumas seleções campeãs entre os favoritos.
Antes da Copa de 2014, a Alemanha aparecia entre os principais candidatos em diversos modelos. Em 2018, a França figurava consistentemente entre os favoritos. Em 2022, a Argentina também aparecia entre as seleções com maiores probabilidades de conquista do torneio em diferentes sistemas de previsão.


Esses acertos frequentemente chamam atenção da imprensa e ajudam a popularizar os modelos.
Mas a história não termina aí.
…e quando eles erram feio
A Copa do Mundo também está cheia de exemplos que mostram os limites da previsão estatística.
Em 2018, alguns modelos acadêmicos apontavam a Alemanha como favorita ao título. Um estudo baseado em rankings Elo e simulações de Monte Carlo indicava os alemães como os candidatos mais fortes ao troféu.
O que aconteceu? A Alemanha foi eliminada ainda na fase de grupos.
Foi uma das maiores surpresas da história recente do torneio e um lembrete poderoso de que o futebol continua sendo um ambiente altamente imprevisível.


Lesões, expulsões, erros de arbitragem, decisões táticas e até fatores psicológicos podem alterar completamente o destino de uma competição. Nenhum modelo consegue capturar tudo.
A Copa do Mundo como laboratório da incerteza
Talvez seja justamente por isso que tantos pesquisadores se interessam pelo tema.
Para Achim Zeileis, pesquisador da University of Innsbruck e colaborador de diversos projetos de previsão esportiva, grandes torneios representam uma oportunidade única para aproximar o público dos conceitos de probabilidade e estatística. Afinal, poucas situações ilustram tão bem a diferença entre possibilidade e certeza quanto uma Copa do Mundo.
Uma seleção pode ser a favorita, mas isso não significa que ela vencerá. Uma equipe pode ter apenas 5% de chance de conquistar o título, mas isso não significa que seja impossível.
Na linguagem da ciência de dados, ambos os cenários são perfeitamente compatíveis.
Muito além do futebol
No fundo, a história dos algoritmos que tentam prever a Copa do Mundo não é apenas uma história sobre esporte. Ela é uma história sobre como lidamos com a incerteza.
Os mesmos conceitos utilizados para estimar as chances de uma seleção chegar à final também aparecem em áreas como saúde, economia, logística e segurança pública.
Em todos esses contextos, o objetivo não é prever o futuro com perfeição, é compreender padrões, medir riscos e tomar decisões melhores com base nos dados disponíveis.
Talvez por isso a Copa do Mundo seja tão fascinante para cientistas de dados, porque ela nos lembra de algo fundamental: mesmo em uma era de algoritmos avançados, aprendizado de máquina e IA, ainda existem acontecimentos que escapam das previsões.
Mas diante da incerteza, conhecimento e probabilidade costumam ser aliados muito mais valiosos do que qualquer palpite.