O Insight recebe durante os próximos meses os estudantes Taya Mohamed Abderrahman e Mohammad Abboud, vindos da Mauritânia e Itália, respectivamente. Ambos estão contribuindo com suas pesquisas no Laboratório Insight como alunos intercambistas.
Taya é aluno de graduação do curso de Engenharia em Inteligência Artificial da Université Mohammed VI Polytechnique – EMINES, no Marrocos. O estudante estará fazendo um estágio no Insight Lab por um período de dois meses com sua pesquisa na área de Processamento de Linguagem Natural intitulada: Improving named entity recognition using Deep Learning with human in the coops (NERD).
Esse intercâmbio é possível graças à parceria entre a Universidade Federal do Ceará (UFC) e diversas universidades no mundo, assim, alunos das áreas de engenharia vêm desenvolver suas pesquisas nos laboratórios de pesquisa da UFC.
Já o aluno Mohammad está cursando doutorado na Universidade de Versalhes Saint Quentin en Yvelines – Paris Saclay. Mohammad estará em missão de pesquisa por um período de um mês aqui no Insight, e sua vinda é fruto da parceria entre o laboratório Insight e o projeto Master. O pesquisador tem seu trabalho intitulado em: Learning from a mass of multidimensional Times Series in the context of Internet of things.
O projeto Master é coordenado pela Professora Chiara Renso, Doutora em Ciência da Computação, pesquisadora sênior do Instituto ISTI – CNR e integrante do conselho nacional de pesquisa da Itália.
Projeto Master
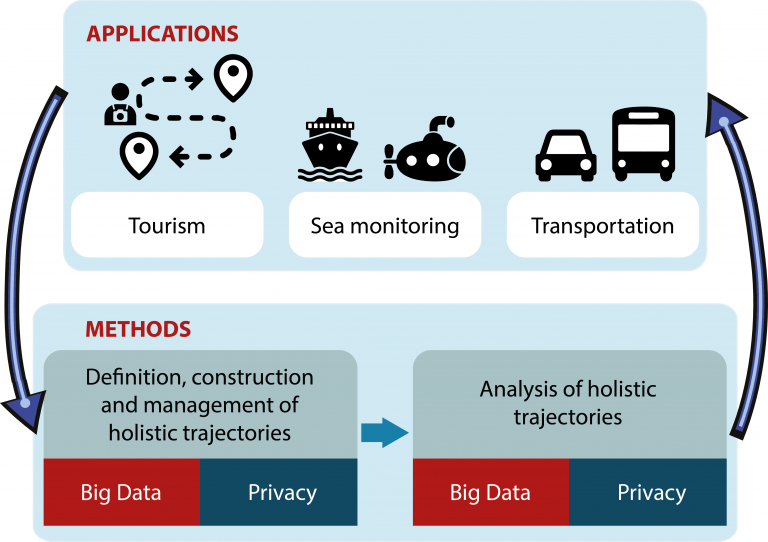
O objetivo do projeto Master, sediado na Itália, é formar uma rede internacional e intersetorial de organizações trabalhando em um programa de pesquisa conjunta para definir novos métodos para construir, gerenciar e analisar trajetórias semânticas de múltiplos aspectos. O projeto propõe métodos para analisar e inferir conhecimento a partir de trajetórias de múltiplos aspectos, considerando como questões vitais as dimensões de privacidade e big data como demonstra a imagem abaixo. O laboratório Insight, por meio da UFC, é um dos três parceiros brasileiros desse projeto.
O cenário das linguagens de programação é valioso e está em expansão, o que pode dificultar o foco em apenas uma para sua carreira. Destacamos algumas das linguagens mais populares que são modernas, amplamente utilizadas e vêm com muitos pacotes ou bibliotecas que ajudarão na produtividade e eficiência de seu trabalho.
“A única maneira de aprender uma nova linguagem de programação é escrevendo programas nela.” Dennis Ritchie.
Todos estão tentando entrar no cenário do desenvolvimento de aplicativos, pois oferece algumas das carreiras mais bem pagas, como Desenvolvimento Web, Ciência de Dados, Inteligência Artificial e muito mais.
Mas antes de iniciar uma carreira e criar seu primeiro aplicativo, você precisa escolher uma entre as mais de 700 linguagens de programação disponíveis.
Se você planeja fazer sua escolha, sugerimos algo mais moderno, amplamente usado e com muitos pacotes ou bibliotecas.
Mas não se preocupe, a lista a seguir tornará essa escolha o mais fácil possível para você ao analisar algumas linguagens de programação populares e seus usos.
1. Python — Inteligência Artificial e Aprendizado de Máquina
Nível: Iniciante.
Frameworks populares: Django, Flask.
Plataforma: Web, Desktop.
Popularidade: nº 1 no índice de popularidade do PYPL de março de 2021, nº 3 no índice Tiobe de março de 2021, querido por 66,7% dos desenvolvedores do StackExchange em 2020 e mais desejado por 30% do que qualquer outra linguagem.
Desenvolvido por Guido van Rossum na década de 1990, o Python multifuncional de alto nível cresceu extremamente rápido ao longo dos anos para se tornar uma das linguagens de programação mais populares atualmente.
E a principal razão para a sua popularidade é a sua facilidade para iniciantes, que permite que qualquer pessoa, mesmo sem experiência em programação, inicie no Python e comece a criar programas simples.
Mas isso não é tudo. Ele também oferece uma coleção excepcionalmente vasta de pacotes e bibliotecas que podem desempenhar um papel fundamental na redução do ETA para seus projetos, juntamente com uma forte comunidade de desenvolvedores com ideias semelhantes.
Para que serve:
Embora o Python possa ser usado para construir praticamente qualquer coisa, ele realmente se destaca quando se trata de trabalhar em tecnologias como Inteligência Artificial, Machine Learning e Data Analytics. Python também se mostra útil para desenvolvimento web, criação de aplicativos corporativos e GUIs para aplicativos .
Popularidade: 3º no Índice de popularidade do PYPL de março de 2021, 7º no Índice Tiobe de março de 2021, querido por 58,3% dos desenvolvedores do StackExchange em 2020 e o mais desejado do que qualquer outra linguagem por 18,5%.
JavaScript foi uma das principais linguagens de programação ao lado de HTML e CSS que ajudaram a construir a internet. Essa linguagem foi criada em 1995 pela Netscape, a empresa que lançou o famoso navegador Netscape Navigator, para eliminar a grosseria das páginas estáticas e adicionar uma pitada de comportamento dinâmico a elas.
Hoje, o JavaScript tornou-se uma linguagem de programação multiparadigma de alto nível que serve como a principal linguagem de programação front-end do mundo para a web, lidando com todas as interações oferecidas pelas páginas da web, como pop–ups, alertas, eventos e muito mais.
Para que serve:
JavaScript é a opção perfeita se você deseja que seu aplicativo seja executado em vários dispositivos, como smartphones, nuvem, contêineres, microcontroladores e em centenas de navegadores. Para as cargas de trabalho do lado do servidor, existe o Node.js, um runtime JavaScript comprovado que está sendo usado por milhares de empresas atualmente.
3. Java – Desenvolvimento de Aplicativos Corporativos
Nível: Intermediário;
Frameworks populares: Spring, Hibernate, Strut;
Plataforma: Web, Mobile, Desktop;
Popularidade: 2º no Índice de Popularidade do PYPL de março de 2021, 2º no Índice Tiobe de março de 2021, querido por 44,1% dos desenvolvedores do StackExchange em 2020.
Java continua sendo a linguagem de programação para a construção de aplicativos de nível empresarial há mais de 20 anos.
Criada por James Gosling da Sun Microsystems em 1995, a linguagem de programação orientada a objetos Java tem servido como uma ferramenta segura, confiável e escalável para desenvolvedores desde então.
Alguns dos recursos oferecidos pelo Java que o tornam mais preferível do que várias outras linguagens de programação são seus recursos de coleta de resíduos, compatibilidade com versões anteriores, independência de plataforma via JVM, portabilidade e alto desempenho.
A popularidade do Java pode ser vista claramente entre os membros da Fortune 500, pois 90% deles usam Java para gerenciar seus negócios com eficiência.
Para que serve:
Além de ser usado para desenvolver aplicativos de negócios robustos, o Java também tem sido amplamente usado no Android, tornando-se um pré-requisito para desenvolvedores Android. Java também permite que os desenvolvedores criem aplicativos para uma variedade de setores, como bancos, comércio eletrônico, bem como aplicativos para computação distribuída.
Popularidade: 7º no Índice de Popularidade do PYPL de março de 2021.
Se você faz algum tipo de análise de dados ou trabalha em projetos de Machine Learning, é provável que já tenha ouvido falar sobre R. A linguagem de programação R foi lançada ao público pela primeira vez em 1993 por seus criadores Ross Ihaka e Robert Gentleman como uma implementação da linguagem de programação S, com foco especial em computação estatística e modelagem gráfica.
Ao longo dos anos, o R se tornou uma das melhores linguagens de programação para projetos que exigem extensa análise de dados, modelagem gráfica de dados, análise espacial e de séries temporais.
O R também oferece grande extensibilidade por meio de suas funções e extensões que oferecem várias técnicas e recursos especializados para desenvolvedores. Essa linguagem também funciona consideravelmente bem com código de outras linguagens de programação, como C, C++, Python, Java e .NET.
Para que serve:
Além de alguns dos usos mencionados acima, o R pode ser usado para análise de comportamento, ciência de dados e projetos de aprendizado de máquina que envolvem classificação, clustering e muito mais.
5. C/C++ — Sistemas Operacionais e Ferramentas do Sistema
Nível: C – Intermediário a Avançado, C++ Iniciante a Intermediário;
Estruturas populares: MFC, .Net, Qt, KDE, GNOME;
Plataforma: Móvel, Desktop, Incorporado.
Acredite ou não, as linguagens de programação C/C++ estavam na moda no final do século 20. Por quê?
Porque C e C++ são linguagens de programação de nível muito baixo, oferecendo desempenho extremamente rápido, e é por isso que eles foram e ainda são usados para desenvolver sistemas operacionais, sistemas de arquivos e outros aplicativos de nível de sistema.
Enquanto o C foi lançado nos anos 70 por Dennis Ritchie, o C++, uma extensão para C com classes e muitas outras adições, como recursos orientados a objetos, foi lançado posteriormente por Bjarne Stroustrup em meados dos anos 80.
Mesmo depois de quase 50 anos, ambas as linguagens de programação ainda são usadas para criar aplicações estáveis e também algumas das mais rápidas de todos os tempos.
Para que serve:
Como C e C++ oferecem acesso total ao hardware subjacente, eles têm sido usados para criar uma ampla variedade de aplicativos e plataformas, como aplicativos de sistema, sistemas em tempo real, IoT, sistemas embarcados, jogos, nuvem, contêineres e muito mais.
Plataforma: Multiplataforma, principalmente desktop;
Popularidade: querido por 62,3% dos desenvolvedores do StackExchange em 2020 e desejado mais do que qualquer outra linguagem por 17,9%.
Go, ou Golang, é uma linguagem de programação compilada desenvolvida pelo gigante das buscas Google. Criado em 2009, o Golang é um esforço dos designers do Google para eliminar todas as falhas nos idiomas usados em toda a organização e manter intactos os melhores recursos.
Golang é rápido e tem uma sintaxe simples, permitindo que qualquer pessoa aprenda a linguagem de programação. Ele também vem com suporte multiplataforma, tornando o uso fácil e eficiente.
Essa linguagem afirma oferecer uma combinação de alto desempenho como C/C++, simplicidade e usabilidade como Python, além de manipulação eficiente de simultaneidade como Java.
Para que serve:
Go é usado principalmente em tecnologias de back-end, serviços em nuvem, redes distribuídas, IoT, mas também tem sido usado para criar utilitários de console, aplicativos GUI e aplicativos da web.
7. C# — Desenvolvimento de aplicativos e Web usando .NET
Nível: Intermediário;
Estruturas populares: .NET, Xamarin;
Plataforma: multiplataforma, incluindo aplicativos de software móveis e corporativos;
Popularidade: 4º no Índice de popularidade do PYPL de março de 2021, 5º no Índice Tiobe de março de 2021, querido por 59,7% dos desenvolvedores do StackExchange em 2020.
C# foi a abordagem da Microsoft para desenvolver uma linguagem de programação semelhante ao C orientado a objetos como parte de sua iniciativa .NET. A linguagem de programação multiparadigma de propósito geral foi revelada em 2000 por Anders Hejlsberg e tem uma sintaxe semelhante a C, C++ e Java.
Este foi um grande ponto positivo para os desenvolvedores que estavam familiarizados com qualquer uma dessas linguagens. Ele também oferecia compilação e execução relativamente mais rápidas, além de escalabilidade perfeita.
C# foi projetado tendo em mente o ecossistema .NET, que permite aos desenvolvedores acessar uma variedade de bibliotecas e frameworks oferecidos pela Microsoft. E com a integração com o Windows, o C# se torna extremamente fácil de usar, perfeito até mesmo para desenvolver aplicativos baseados no Windows.
Para que serve:
Os desenvolvedores podem usar C# para uma variedade de projetos, incluindo desenvolvimento de jogos, programação do lado do servidor, desenvolvimento da Web, criação de formulários Web, aplicativos móveis e muito mais. C# também tem sido usado para desenvolver aplicativos para a plataforma Windows, especificamente Windows 8 e 10.
Plataforma: Multiplataforma (desktop, mobile, web) Scripting web de back-end;
Popularidade: 6º no Índice de popularidade do PYPL de março de 2021 e 8º no Índice Tiobe de março de 2021.
Assim como o Python de Guido van Rossum, o PHP também se concretizou como um projeto paralelo de Rasmus Lerdorf, com o desenvolvimento inicial remontando ao ano de 1994.
A versão do PHP de Rasmus foi originalmente destinada a ajudá-lo a manter sua página pessoal, mas ao longo dos anos, o projeto evoluiu para suportar formulários e bancos de dados da web.
Hoje, o PHP tornou-se uma linguagem de script de uso geral que está sendo usada em todo o mundo, principalmente para desenvolvimento web. É rápido, simples e independente de plataforma, juntamente com uma grande comunidade de software de código aberto.
Para que serve:
Um grande número de empresas está usando PHP hoje para criar ferramentas como CMS (Content Management Systems), plataformas de comércio eletrônico e aplicativos da web. O PHP também torna extremamente fácil criar páginas da web rapidamente.
9. SQL — Gerenciamento de dados
Nível: Iniciante;
Plataforma: gerenciamento de banco de dados back–end;
Popularidade: 10º no Tiobe Index em março de 2021, querido por 56,6% dos desenvolvedores do StackExchange em 2020.
SQL, abreviação de Structured Query Language, é provavelmente uma das linguagens de programação mais importantes nesta lista.
Projetada por Donald D. Chamberlin e Raymond F. Boyce em 1974, a linguagem de programação de propósito específico tem desempenhado um papel fundamental ao permitir que os desenvolvedores criem e gerenciem tabelas e bancos de dados para armazenar dados relacionais em centenas de milhares de campos de dados.
Sem o SQL, as organizações teriam que confiar em métodos mais antigos e possivelmente mais lentos de armazenamento e acesso a grandes quantidades de dados. Com essa linguagem, muitas dessas tarefas podem ser feitas em segundos.
Ao longo dos anos, o SQL ajudou a gerar um grande número de RDBMS (Relational Database Management Systems) que oferecem muito mais do que apenas a criação de tabelas e bancos de dados.
Para que serve:
Praticamente todos os outros projetos ou indústrias que precisam lidar com grandes quantidades de dados armazenados em tabelas ou bancos de dados usam SQL por meio de um RDBMS.
Plataforma: Mobile (aplicativos Apple iOS, especificamente);
Popularidade: 9º no Índice de popularidade do PYPL de março de 2021, querido por 59,5% dos desenvolvedores do StackExchange em 2020.
O controle total da Apple sobre seu hardware e software permitiu que ela oferecesse experiências suaves e consistentes em toda a sua gama de dispositivos. E é aí que entra o Swift.
Swift é a própria linguagem de programação da Apple que foi lançada em 2014 como um substituto para sua linguagem de programação Objective-C. É uma linguagem de programação multiparadigma de propósito geral extremamente eficiente e projetada para melhorar a produtividade do desenvolvedor.
Swift é uma linguagem de programação moderna (a mais nova nesta lista), rápida, poderosa e oferece total interoperabilidade com Objective-C. Ao longo dos anos, o Swift recebeu inúmeras atualizações que o ajudaram a ganhar popularidade significativa entre as plataformas iOS, macOS, watchOS e tvOS da Apple.
Para que serve:
Emparelhado com a estrutura Cocoa e Cocoa Touch da Apple, o Swift pode ser usado para criar aplicativos para praticamente todos os dispositivos Apple, como iPhones, iPads, Mac, Watch e outros dispositivos.
Cada linguagem de programação tem seu próprio conjunto de benefícios e, de todas as entradas, você pode inserir o campo de sua escolha.
Dominar o Python pode ajudar você a conseguir um dos 3 cargos mais bem pagos do setor. Com o Python, você pode se candidatar a Engenheiro(a) de Software, Engenheiro(a) DevOps, Cientista de Dados e pode até garantir cargos nas empresas mais renomadas com um pacote atraente.
Você pode simplesmente optar por Quantitative Analyst, Data Visualization, Expert, Business Intelligence Expert e Data Analyst with R. Em relação ao JavaScript, há uma grande demanda por desenvolvedores nessa linguagem.
Mas não há como superar a eficiência do C/C++ quando se trata de construir ferramentas de sistema e sistemas operacionais, pois continua a ocupar o primeiro lugar no índice de qualidade de software da TIOBE.
O SQL continua sendo uma das melhores linguagens de programação para mexer em grandes bancos de dados, enquanto o C# se mostra perfeito para o Windows. Swift também tem visto um aumento na popularidade entre os desenvolvedores que procuram construir para o hardware da Apple. Quanto ao PHP e Go continuam mantendo uma posição respeitável na indústria.
Então, das 10 linguagens de programação, depende somente de você decidir qual adequa-se melhor à sua carreira. Logo, escolha sabiamente!
Esperamos ter ajudado com esta escolha. Continuem acompanhando nossas postagens por aqui!
A Secretaria do Planejamento e Gestão do Ceará (Seplag-CE), por meio da sua secretaria executiva do Planejamento e Orçamento, realizou, no dia 30 de maio, o I Encontro de Ciência e Tecnologia para o Desenvolvimento Social. O evento realizado em parceria com a Fundação Cearense de Apoio ao Desenvolvimento Científico e Tecnológico (Funcap), vinculada à Secretaria da Ciência, Tecnologia e Educação Superior do Estado do Ceará (Secitece), aconteceu no auditório da Seplag.
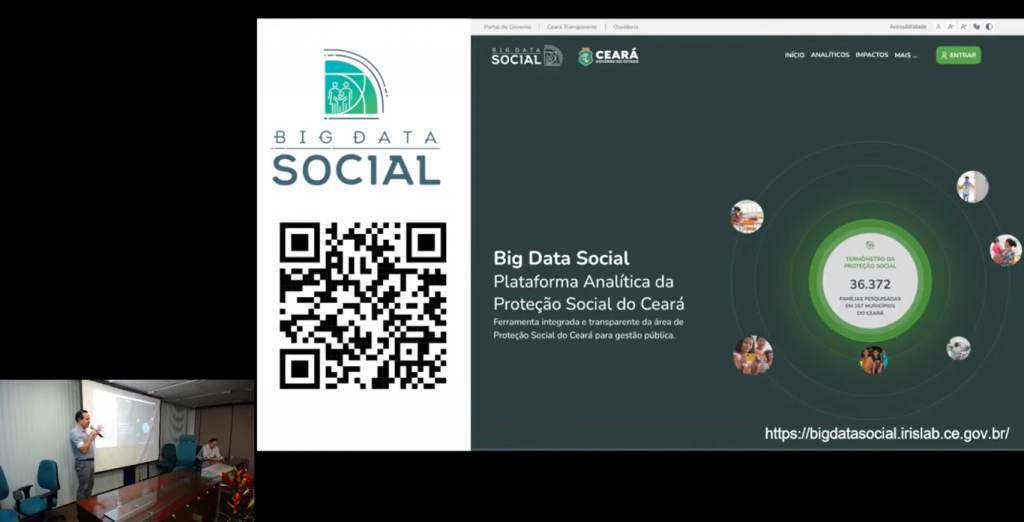
Apresentação da Plataforma Big Data Social
Na ocasião, José Macêdo, cientista-chefe da Transformação Digital e coordenador do Insight Lab, apresentou a plataforma Big Data Social do Governo do Ceará e sua equipe de trabalho. Estavam presentes também os cientistas-chefes: Flávio Ataliba (Economia), Márcia Machado (Proteção Social) e Jorge Lira (Educação).
Imagem: Apresentação Big Data Social
Imagem: Apresentação Big Data Social
No evento foram apresentados os temas aplicados por meio da gestão pública que causaram impactos e estão contribuindo para o progresso social aliado ao advento da tecnologia e a popularização da ciência, e a formação de cidadãos sociais e culturais no contexto tecnológico.
Segundo Flávio Ataliba, secretário executivo do Planejamento e Orçamento da Seplag, o evento surgiu para apresentar os resultados das pesquisas realizadas nas áreas citadas, além de servir como um momento rico para o compartilhamento de conhecimentos e de novas ideias.
O encontro também teve o apoio da Escola de Gestão Pública do Estado do Ceará (EGPCE) a Universidade Federal do Ceará (UFC), a Fundação Cearense de Apoio ao Desenvolvimento Científico e Tecnológico (Funcap), o Laboratório de Inovação de Dados (ÍRIS), os Programas Cientistas Chefes, o Instituto de Pesquisa e Estratégia Econômica do Ceará (Ipece), a Secretaria da Proteção Social, Justiça Cidadania, Mulheres e Direitos Humanos, a Secretaria da Educação e a Vice-Governadoria do Ceará.
José Macêdo, cientista-chefe do Departamento de Computação da Universidade Federal do Ceará (UFC), foi um dos 12 homenageados com a Medalha Ordem do Mérito no aniversário de quatro anos de fundação da Superintendência de Pesquisa e Estratégia de Segurança Pública (Supesp), ocorrido na tarde do dia 26 de maio na sede da Secretaria da Segurança e Defesa Social (SSPDS-CE).
Na ocasião, aconteceu a cerimônia de entrega da “Medalha Ordem do Mérito Supesp” que contou também com a presença de titulares e representantes vinculadas à secretaria de segurança, da vice-governadoria e convidados do programa Cientista-chefe, que é uma parceria entre o Governo do Ceará e a Universidade Federal do Ceará (UFC) por meio do Insight Lab.
A cerimônia teve a presença da banda Major Xavier Torres, da Polícia Militar do Ceará, além da exibição do vídeo institucional da Supesp, por meio do qual os convidados puderam conhecer melhor as diretorias, as gerências, as atividades e algumas ferramentas tecnológicas desenvolvidas.
José Macêdo fala sobre a medalha Ordem do Mérito Supesp
Uma das personalidades contempladas com a homenagem da Supesp, José Macêdo, fala sobre a honraria.
“Este evento serviu para comemorar o aniversário de 4 anos da SUPESP e agraciar profissionais que tem contribuído para a segurança pública do governo do Ceará. Fico muito feliz pelo reconhecimento ao meu trabalho como cientista-chefe da seguraça pública entre os anos de 2018-2020. Me sinto honrado e realizado em poder contribuir para melhorar a segurança pública do Estado do Ceará.”
Time Insight da esquerda para direita, Emanuele Santos, José Macêdo, Regis Pires, José Florêncio, Ticiane Linhares e Marianna Gonçalves.
Medalha Ordem do Mérito Supesp
Imagem: Supesp.ce.gov.br
A medalha é a primeira honraria outorgada pela Supesp e tem como objetivo condecorar personalidade civis, bombeiros militares, policiais civis e militares que, comprovadamente, tenham colaborado de forma emérita para o desenvolvimento das atividades próprias da Supesp, em ser referência nacional e internacional na realização de pesquisas, estudos e análises criminais com a missão de realizar projetos estratégicos para o fortalecimento da formulação das políticas de segurança pública do estado do Ceará.
Os homenageados
Em sua primeira edição, a honraria homenageou 12 personalidades. Além do Profº José Macêdo, cientista-chefe do Departamento de Computação da Universidade Federal do Ceará (UFC) foram agraciados, o secretário da SSPDS, Sandro Caron; o secretário executivo da SSPDS, Samuel Elânio; o secretário executivo de Planejamento e Gestão Interna da SSPDS, Adriano Sales; o coronel comandante geral da Polícia Militar do Ceará, Márcio de Oliveira; o delegado geral da Polícia Civil do Ceará, Sérgio Pereira; o perito geral da Perícia Forense do Ceará, Júlio Torres; o coronel comandante geral do Corpo de Bombeiros Militar do Estado do Ceará, Ronaldo Roque de Araújo; o diretor geral da Academia Estadual de Segurança Pública do Ceará, Clairton de Abreu; a assessora especial da governadora do Ceará, Carla da Escóssia; o presidente da Fundação Cearense de Apoio ao Desenvolvimento Científico e Tecnológico (Funcap), Tarcísio Haroldo Cavalcante Pequeno; e o assessor de Programas e Projetos da vice-governadoria, Régis Dantas Façanha.
Ação Solidária no aniversário de 4 anos da Supesp
A campanha “Fazer o bem é dado positivo” continua recebendo doações. A ação solidária também faz parte da programação em alusão ao quarto ano de criação da Supesp e já arrecadou mais de 400 quilos de alimentos e 15 quilos de material reciclável.
As doações beneficiarão famílias em situação de vulnerabilidade social, no bairro Bom Jardim, em Fortaleza, além de catadores registrados da Associação dos Agentes Ambientais Rosa Virgínia, do bairro Parque Santa Rosa, conveniados com o Departamento de Proteção Ambiental da UFC.
Está aberta a seleção para Bolsista Desenvolvedor ou Pesquisador – Cientista de Dados para os laboratórios Insight Lab e ÍRIS
O Insight Lab é um laboratório de pesquisa aplicada em Ciência de Dados e Inteligência Artificial da Universidade Federal do Ceará, envolvendo mais de 100 pessoas, entre pesquisadores, alunos de graduação, mestrado, doutorado e especialistas associados. O ÍRIS é um Laboratório de Inovação e Dados na Casa Civil do Governo do Estado do Ceará, que visa acelerar soluções inovadoras para Transformação Digital do estado.
Você será responsável por
Atuar no desenvolvimento de pesquisas relacionadas à descoberta de conhecimento usando ciência de dados e algoritmos de aprendizagem de máquina.
Integrar dados de bases heterogêneas identificando possíveis inconsistências.
Escrever artigos científicos e experimentar diferentes algoritmos de ciência de dados.
Procuramos por pessoas
Altamente criativas e curiosas sobre os assuntos, produtos, serviços e pesquisas científicas do Insight Lab;
Que tenham habilidades interpessoais e de comunicação;
Que saibam trabalhar bem em equipe e com uma gama de pessoas criativas;
Que saibam gerenciar demandas de trabalho de forma eficaz e organizada;
Com paixão por criar, aprender e testar novas tecnologias;
Você deve possuir conhecimentos nas seguintes áreas
Ciência de Dados;
Aprendizado de Máquina;
Banco de Dados.
Carga-horária das atividades
Parcial: 20 horas semanais;
Integral: 40 horas semanais.
Etapas da seleção
Primeira fase: análise do histórico e currículo.
Segunda fase: entrevista via videoconferência para os classificados na primeira fase.
Após a análise do histórico e currículo, os candidatos selecionados para a segunda fase deverão participar da entrevista em dia e horário a definir. Os candidatos aprovados para a segunda fase receberão um e-mail informando o dia e horário da entrevista.
Modalidade de Contratação
Contrato de bolsista para graduandos, graduados, mestrandos ou doutorandos da Universidade Federal do Ceará.
Etapas da seleção
Preenchimento do formulário até: 26/04;
Data de divulgação dos resultados da análise de currículo e histórico: 27/04;
Algoritmos de aprendizado de máquina utilizam parâmetros baseados em dados de treinamento – um subconjunto de dados que representa o conjunto maior. À medida que os dados de treinamento se expandem para representar o mundo de modo mais realista, o algoritmo calcula resultados mais precisos.
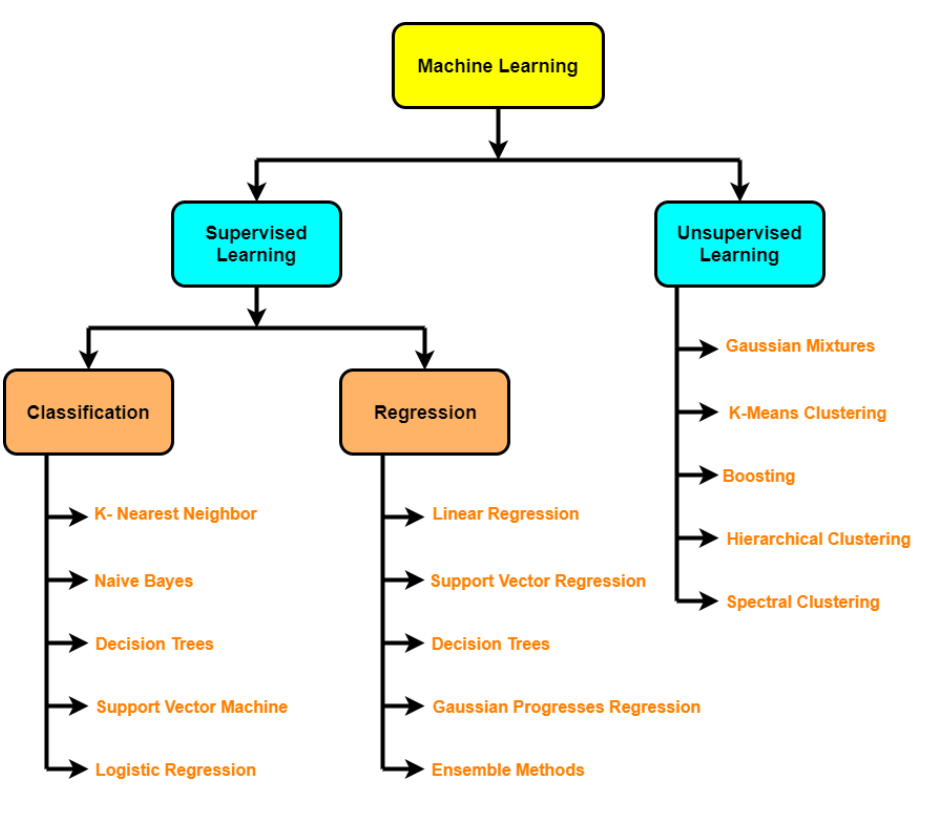
Diferentes algoritmos analisam dados de maneiras diferentes. Geralmente, eles são agrupados pelas técnicas de aprendizado de máquina para as quais são usados: aprendizado supervisionado, aprendizado não supervisionado e aprendizado de reforço. Os algoritmos usados com mais frequência usam a regressão e a classificação para prever categorias de destino, encontrar pontos de dados incomuns, prever valores e descobrir semelhanças.
Tendo isso em mente, vamos conhecer os 5 algoritmos de aprendizado de máquina mais importantes:
Algoritmos de Ensemble Learning;
Algoritmos explicativos;
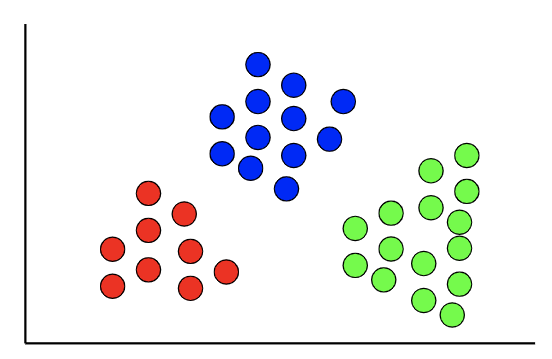
Algoritmos de agrupamento;
Algoritmos de Redução de Dimensionalidade;
Algoritmos de semelhança.
1. Algoritmos de Ensemble Learning (Random Forests, XGBoost, LightGBM, CatBoost)
O que são algoritmos de Ensemble Learning?
Para entender o que eles são, primeiro você precisa saber o que é o Método Ensemble. Esse método consiste no uso simultâneo de vários modelos para obter melhor desempenho do que um único modelo em si.
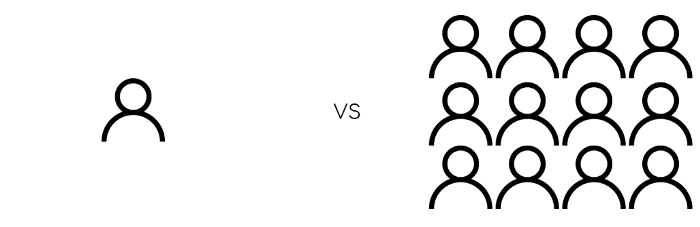
Conceitualmente, considere a seguinte analogia:
Imagem Terence Shin
Imagine a seguinte situação: em uma sala de aula é dado o mesmo problema de matemática para um único aluno e para um grupo de alunos. Nessa situação, o grupo de alunos pode resolver o problema de forma colaborativa, verificando as respostas uns dos outros e decidindo por unanimidade sobre uma única resposta. Por outro lado, um aluno, sozinho, não tem esse privilégio – ninguém mais está lá para colaborar ou questionar sua resposta.
E assim, a sala de aula com vários alunos é semelhante a um algoritmo de Ensemble com vários algoritmos menores trabalhando juntos para formular uma resposta final.
Os algoritmos de Ensemble Learning são mais úteis para problemas de regressão e classificação ou problemas de aprendizado supervisionado. Devido à sua natureza inerente, eles superam todos os algoritmos tradicionais de Machine Learning, como Naïve Bayes, máquinas vetoriais de suporte e árvores de decisão.
Algoritmos explicativos permitem identificar e compreender variáveis que possuem relação estatisticamente significativa com o resultado. Portanto, em vez de criar um modelo para prever valores da variável de resposta, podemos criar modelos explicativos para entender as relações entre as variáveis no modelo.
Do ponto de vista da regressão, há muita ênfase nas variáveis estatisticamente significativas. Por quê? Quase sempre, você estará trabalhando com uma amostra de dados, que é um subconjunto de toda a população. Para tirar conclusões sobre uma população, dada uma amostra, é importante garantir que haja significância suficiente para fazer uma suposição confiável.
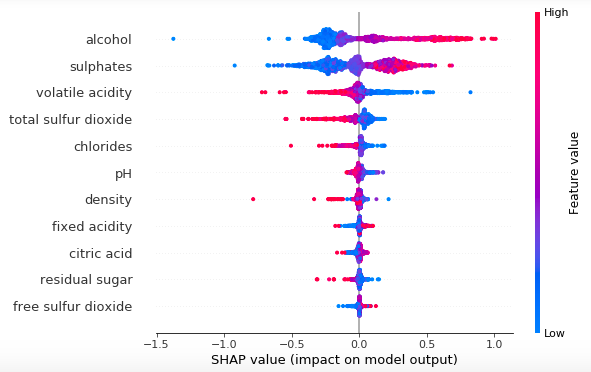
Imagem Terence Shin
Recentemente, também houve o surgimento de duas técnicas populares, SHAP e LIME, que são usadas para interpretar modelos de Machine Learning.
Quando são úteis?
Modelos explicativos são úteis quando você quer entender “por que” uma decisão foi tomada ou quando você quer entender “como” duas ou mais variáveis estão relacionadas entre si.
Na prática, a capacidade de explicar o que seu modelo de Machine Learning faz é tão importante quanto o desempenho do próprio modelo. Se você não puder explicar como um modelo funciona, ninguém confiará nele e ninguém o usará.
Tipos de Algoritmos
Modelos explicativos tradicionais baseados em testes de hipóteses:
Regressão linear
Regressão Logística
Algoritmos para explicar modelos de Machine Learning:
3. Algoritmos de Agrupamento (k-Means, Agrupamento Hierárquico)
Imagem Terence Shin
O que são algoritmos de agrupamento?
Esses algoritmos são usados para realizar análises de agrupamento, que é uma tarefa de aprendizado não supervisionada que envolve o agrupamento de dados. Ao contrário do aprendizado supervisionado, no qual a variável de destino é conhecida, não há variável de destino nas análises de agrupamento.
Quando são úteis?
O clustering é particularmente útil quando você deseja descobrir padrões e tendências naturais em seus dados. É muito comum que as análises de cluster sejam realizadas na fase de EDA, para descobrir mais informações sobre os dados.
Da mesma forma, o agrupamento permite identificar diferentes segmentos dentro de um dataset com base em diferentes variáveis. Um dos tipos mais comuns de segmentação por cluster é a segmentação de usuários/clientes.
Tipos de Algoritmos
Os dois algoritmos de agrupamento mais comuns são agrupamento k-means e agrupamento hierárquico, embora existam muitos mais:
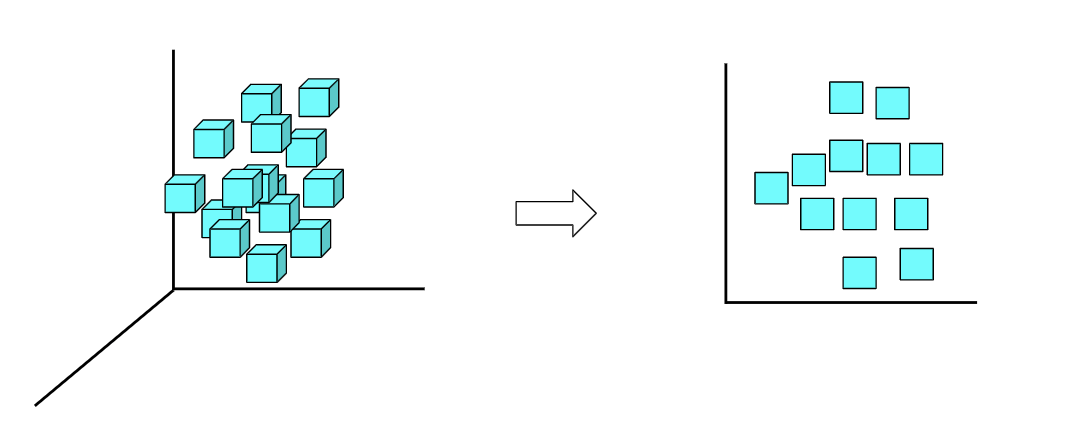
4. Algoritmos de Redução de Dimensionalidade (PCA, LDA)
O que são algoritmos de redução de dimensionalidade?
Os algoritmos de redução de dimensionalidade referem-se a técnicas que reduzem o número de variáveis de entrada (ou variáveis de recursos) em um dataset. A redução de dimensionalidade é essencialmente usada para lidar com a maldição da dimensionalidade, um fenômeno que afirma, “à medida que a dimensionalidade (o número de variáveis de entrada) aumenta, o volume do espaço cresce exponencialmente resultando em dados esparsos.
Quando são úteis?
As técnicas de redução de dimensionalidade são úteis em muitos casos:
Eles são extremamente úteis quando você tem centenas ou até milhares de recursos em um dataset e precisa selecionar alguns.
Eles são úteis quando seus modelos de ML estão super ajustando os dados, o que implica que você precisa reduzir o número de recursos de entrada.
Tipos de Algoritmos
Abaixo estão os dois algoritmos de redução de dimensionalidade mais comuns:
Algoritmos de similaridade são aqueles que computam a similaridade de pares de registros/nós/pontos de dados/texto. Existem algoritmos de similaridade que comparam a distância entre dois pontos de dados, como a distância euclidiana, e também existem algoritmos de similaridade que calculam a similaridade de texto, como o Algoritmo Levenshtein.
Quando são úteis?
Esses algoritmos podem ser usados em uma variedade de aplicações, mas são particularmente úteis para recomendação.
Quais artigos o Medium deve recomendar a você com base no que você leu anteriormente?
Qual música o Spotify deve recomendar com base nas músicas que você já gostou?
Quais produtos a Amazon deve recomendar com base no seu histórico de pedidos?
Estes são apenas alguns dos muitos exemplos em que algoritmos de similaridade e recomendação são usados em nossas vidas cotidianas.
Tipos de Algoritmos
Abaixo está uma lista não exaustiva de alguns algoritmos de similaridade. Se você quiser ler sobre mais algoritmos de distância, confira este artigo. E se você também se interessar por algoritmos de similaridade de strings, leia este artigo.
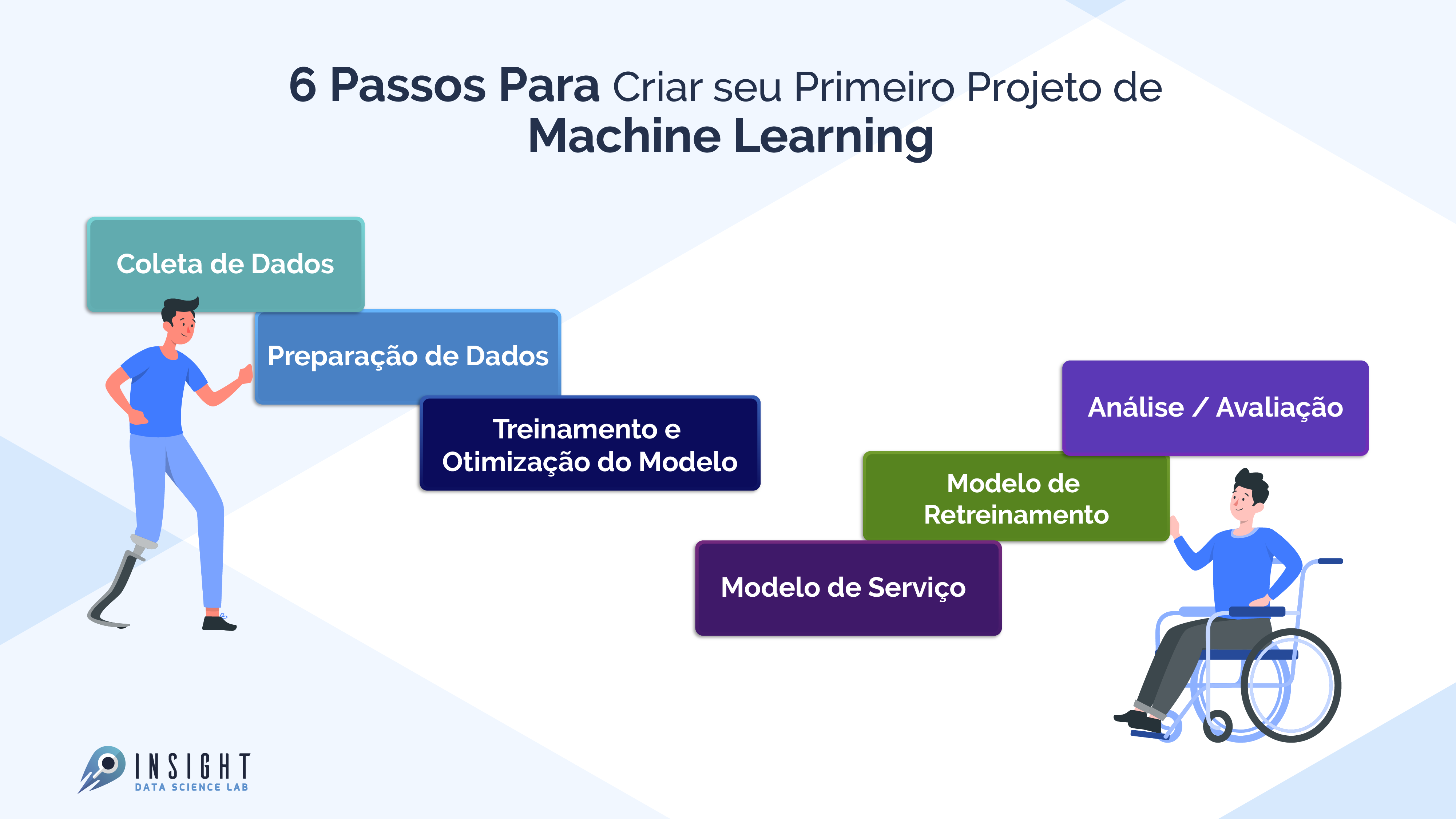
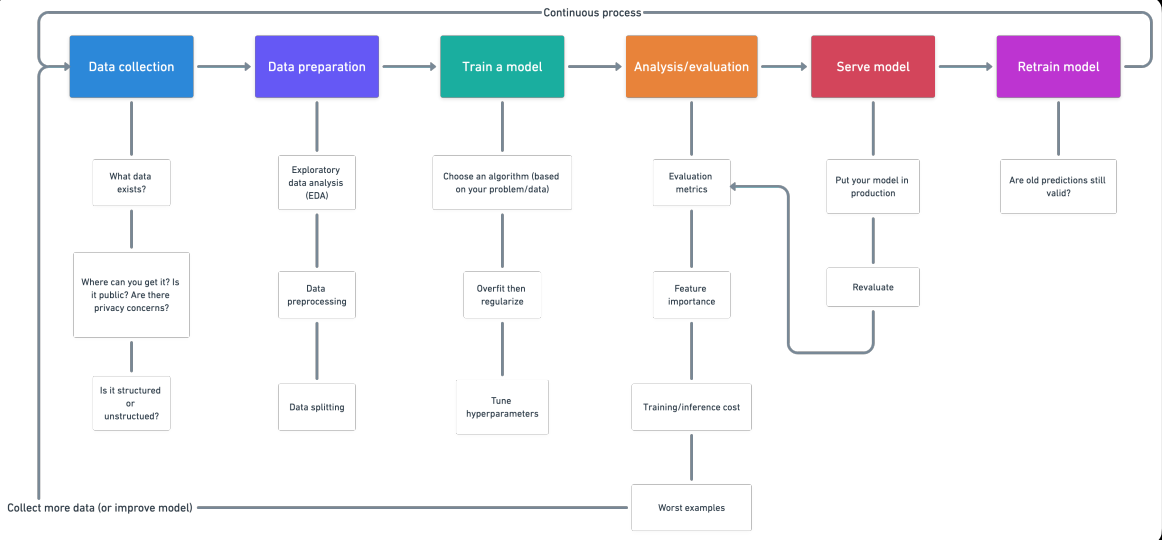
Aqui você verá as várias etapas envolvidas em um projeto de Machine Learning (ML). Existem etapas padrões que você deve seguir para um projeto de Ciência de Dados. Para qualquer projeto, primeiro, temos que coletar os dados de acordo com nossas necessidades de negócios. A próxima etapa é limpar os dados como remover valores, remover outliers, lidar com conjuntos de dados desequilibrados, alterar variáveis categóricas para valores numéricos, etc.
Depois do treinamento de um modelo, use vários algoritmos de aprendizado de máquina e aprendizado profundo. Em seguida, é feita a avaliação do modelo usando diferentes métricas, como recall, pontuação f1, precisão, etc. Finalmente, a implantação do modelo na nuvem e retreiná-lo. Então vamos começar:
Fluxo de trabalho do projeto de Aprendizado de Máquina
1. Coleta de dados
Perguntas a serem feitas:
Que problema deve ser resolvido?
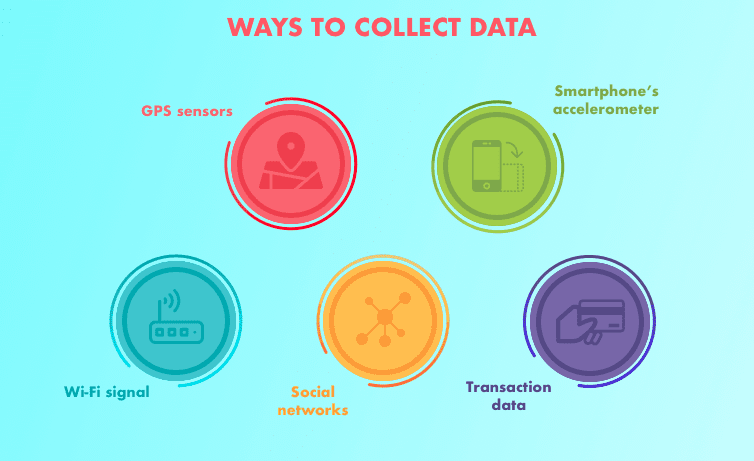
Que dados existem?
Onde você pode obter esses dados? São públicos?
Existem preocupações com a privacidade?
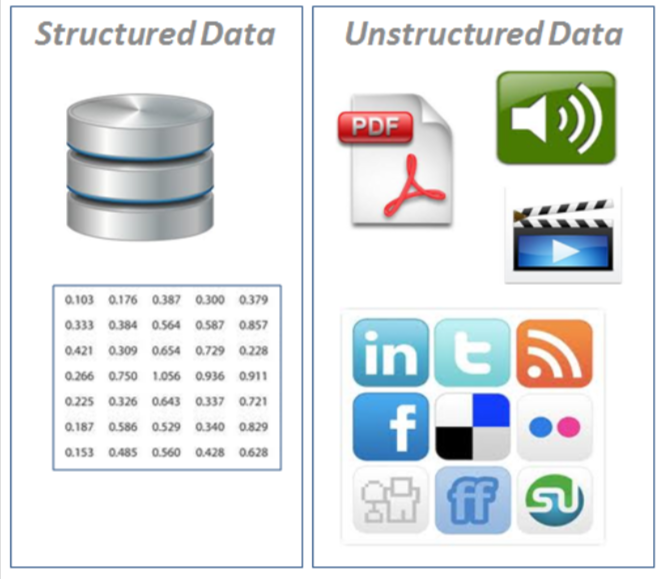
É estruturado ou não estruturado?
Tipos de dados
Dados estruturados: aparecem em formato tabular (estilo linhas e colunas, como o que você encontraria em uma planilha do Excel). Ele contém diferentes tipos de dados, por exemplo: numéricos, categóricos, séries temporais.
Nominal / categórico – Uma coisa ou outra (mutuamente exclusivo). Por exemplo, para balanças de automóveis, a cor é uma categoria. Um carro pode ser azul, mas não branco. Um pedido não importa.
Numérico: qualquer valor contínuo em que a diferença entre eles importa. Por exemplo, ao vender casas o valor de R$ 107.850,00 é maior do que R$ 56.400,00.
Ordinal: Dados que têm ordem, mas a distância entre os valores é desconhecida. Por exemplo, uma pergunta como: como você classificaria sua saúde de 1 a 5? 1 sendo pobre, 5 sendo saudável. Você pode responder 1,2,3,4,5, mas a distância entre cada valor não significa necessariamente que uma resposta de 5 é cinco vezes melhor do que uma resposta de 1.
Séries temporais: dados ao longo do tempo. Por exemplo, os valores históricos de venda de Bulldozers de 2012-2018.
Dados não estruturados: dados sem estrutura rígida (imagens, vídeo, fala, texto em linguagem natural)
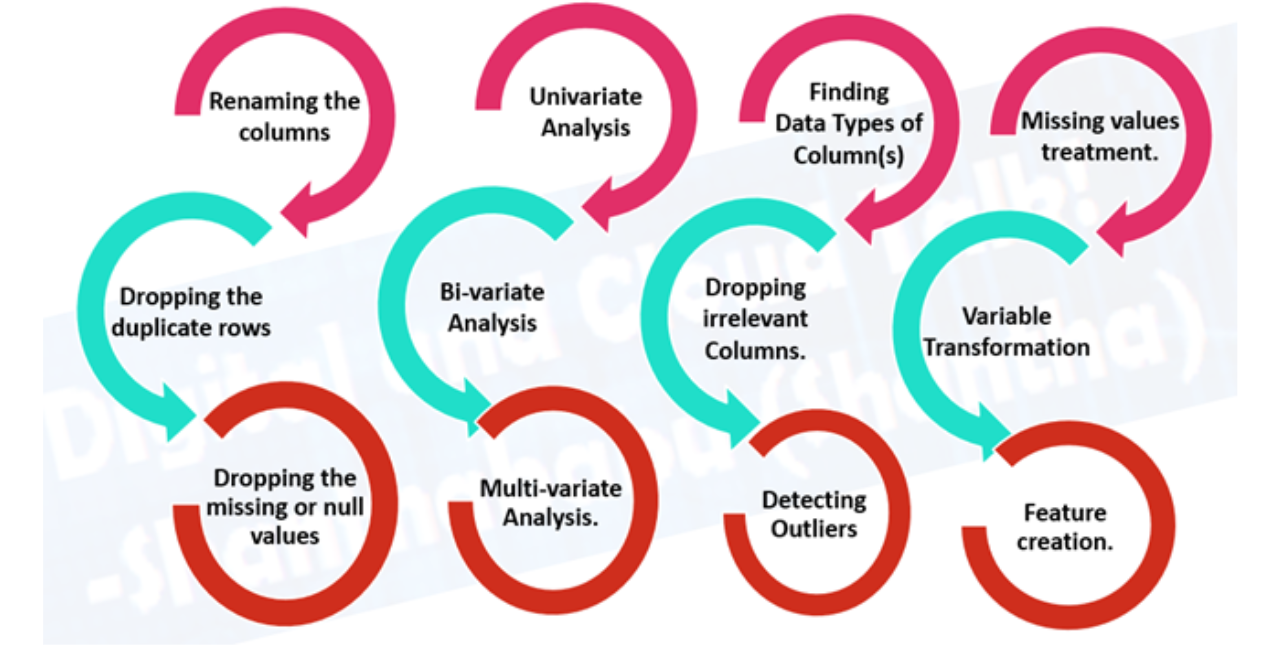
2. Preparação de dados
2.1 Análise Exploratória de Dados (EDA), aprendendo sobre os dados com os quais você está trabalhando
Quais são as variáveis de recursos (entrada) e as variáveis de destino (saída)? Por exemplo, para prever doenças cardíacas, as variáveis de recursos podem ser a idade, peso, frequência cardíaca média e nível de atividade física de uma pessoa. E a variável de destino será a informação se eles têm ou não uma doença.
Que tipo de dado você tem? Estruturado, não estruturado, numérico, séries temporais. Existem valores ausentes? Você deve removê-los ou preenchê-los com imputação de recursos.
Onde estão os outliers? Quantos deles existem? Por que eles estão lá? Há alguma pergunta que você possa fazer a um especialista de domínio sobre os dados? Por exemplo, um médico cardiopata poderia lançar alguma luz sobre seu dataset de doenças cardíacas?
2.2 Pré-processamento de dados, preparando seus dados para serem modelados.
Imputação de recursos: preenchimento de valores ausentes, um modelo de aprendizado de máquina não pode aprender com dados que não estão lá.
Imputação única: Preencha com a média, uma mediana da coluna;
Múltiplas imputações: modele outros valores ausentes e com o que seu modelo encontrar;
KNN (k-vizinhos mais próximos): Preencha os dados com um valor de outro exemplo semelhante;
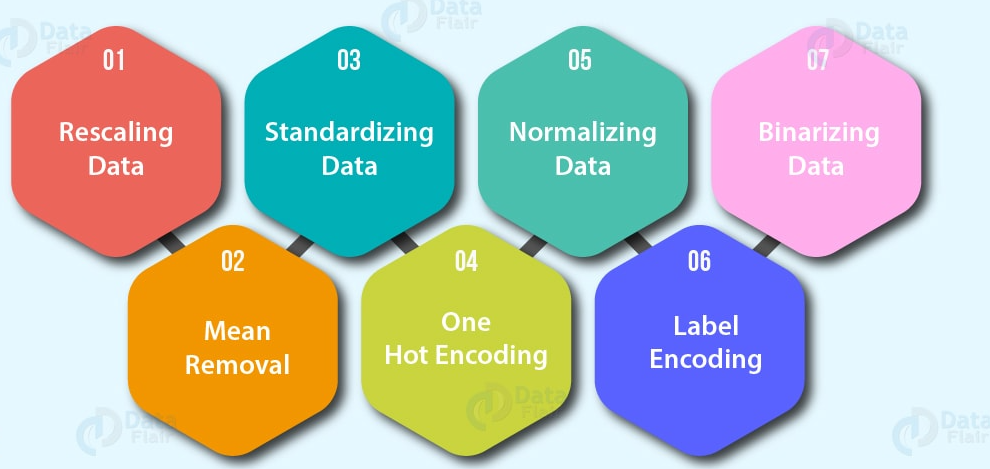
Codificação de recursos (transformando valores em números). Um modelo de aprendizado de máquina exige que todos os valores sejam numéricos.
Uma codificação rápida: Transforme todos os valores exclusivos em listas de 0 e 1, onde o valor de destino é 1 e o resto são 0s. Por exemplo, quando as cores de um carro são verdes, vermelhas, azuis, verdes, o futuro das cores de um carro seria representado como [1, 0 e 0] e um vermelho seria [0, 1 e 0].
Codificador de rótulo:Transforme rótulos em valores numéricos distintos. Por exemplo, se suas variáveis de destino forem animais diferentes, como cachorro, gato, pássaro, eles podem se tornar 0, 1 e 2, respectivamente.
Codificação de incorporação: aprenda uma representação entre todos os diferentes pontos de dados. Por exemplo, um modelo de linguagem é uma representação de como palavras diferentes se relacionam entre si. A incorporação também está se tornando mais amplamente disponível para dados estruturados (tabulares).
Normalização de recursos (dimensionamento) ou padronização: quando suas variáveis numéricas estão em escalas diferentes (por exemplo, number_of_bathroom está entre 1 e 5 e size_of_land entre 500 e 20000 pés quadrados), alguns algoritmos de aprendizado de máquina não funcionam muito bem. O dimensionamento e a padronização ajudam a corrigir isso.
Engenharia de recursos: transforma os dados em uma representação (potencialmente) mais significativa, adicionando conhecimento do domínio.
Decompor;
Discretização: transformando grandes grupos em grupos menores;
Recursos de cruzamento e interação: combinação de dois ou mais recursos;
Características do indicador: usar outras partes dos dados para indicar algo potencialmente significativo.
Seleção de recursos: selecionar os recursos mais valiosos de seu dataset para modelar. Potencialmente reduzindo o overfitting e o tempo de treinamento (menos dados gerais e menos dados redundantes para treinar) e melhorando a precisão.
Redução de dimensionalidade: Um método comum de redução de dimensionalidade, PCA ou análise de componente principal, toma um grande número de dimensões (recursos) e usa álgebra linear para reduzi-los a menos dimensões. Por exemplo, digamos que você tenha 10 recursos numéricos, você poderia executar o PCA para reduzi-los a 3;
Importância do recurso (pós-modelagem): ajuste um modelo a um dataset, inspecione quais recursos foram mais importantes para os resultados e remova os menos importantes;
Os métodos Wrapper geram um subconjunto “candidato”, contendo atributos selecionados no conjunto de treinamento, e utilizam a precisão resultante do classificador para avaliar o subconjunto de atributos “candidatos”.
Lidando com desequilíbrios: seus dados têm 10.000 exemplos de uma classe, mas apenas 100 exemplos de outra?
Colete mais dados (se puder);
Use o pacote scikit-learn-contribimbalanced- learn;
Use SMOTE: técnica desobreamostragem de minoria sintética. Ele cria amostras sintéticas de sua classe secundária para tentar nivelar o campo de jogo.
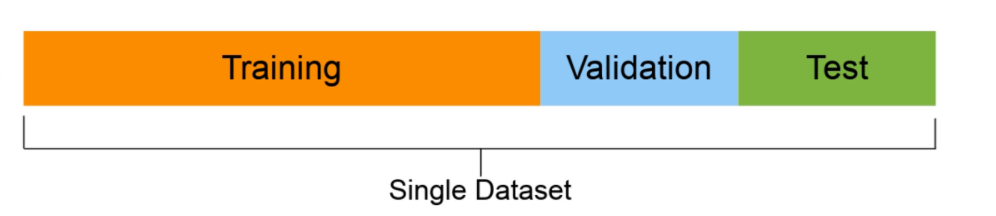
2.3 Divisão de dados
Conjunto de treinamento: geralmente o modelo aprende com 70-80% dos dados;
Conjunto de validação: normalmente os hiperparâmetros do modelo são ajustados com 10-15% dos dados;
Conjunto de teste: geralmente o desempenho final dos modelos é avaliado com 10-15% dos dados. Se você fizer certo os resultados no conjunto de teste fornecerão uma boa indicação de como o modelo deve funcionar no mundo real. Não use este dataset para ajustar o modelo.
Algoritmos não supervisionados – Clustering, redução de dimensionalidade (PCA, Autoencoders, t-SNE), Uma detecção de anomalia.
Tipos de aprendizagem
Aprendizagem em lote;
Aprendizagem online;
Aprendizagem de transferência;
Aprendizado ativo;
Ensembling.
Plataforma para detecção e segmentação de objetos.
Engenharia de atributos
Seleção de atributos
Tipos de Algoritmos e Métodos: Filter Methods, Wrapper Methods, Embedded Methods;
Seleção de Features com Python;
Testes estatísticos: podem ser usados para selecionar os atributos que possuem forte relacionamento com a variável que estamos tentando prever. Os métodos disponíveis são:
f_classif: é adequado quando os dados são numéricos e a variável alvo é categórica.
mutual_info_classif é mais adequado quando não há uma dependência linear entre as features e a variável alvo.
f_regression aplicado para problemas de regressão.
Chi2: Mede a dependência entre variáveis estocásticas, o uso dessa função “elimina” os recursos com maior probabilidade de serem independentes da classe e, portanto, irrelevantes para a classificação;
Recursive Feature Elimination – RFE: Remove recursivamente os atributos e constrói o modelo com os atributos remanescentes, ou seja, os modelos são construídos a partir da remoção de features;
Feature Importance: Métodos ensembles como o algoritmo Random Forest, podem ser usados para estimar a importância de cada atributo. Ele retorna um score para cada atributo, quanto maior o score, maior é a importância desse atributo.
Ajuste e regularização
Underfitting – acontece quando seu modelo não funciona tão bem quanto você gostaria. Tente treinar para um modelo mais longo ou mais avançado.
Overfitting – acontece quando sua perda de validação começa a aumentar ou quando o modelo tem um desempenho melhor no conjunto de treinamento do que no conjunto de testes.
Regularização: uma coleção de tecnologias para prevenir / reduzir overfitting (por exemplo, L1, L2, Dropout, Parada antecipada, Aumento de dados, normalização em lote).
Ajuste de hiperparâmetros – execute uma série de experimentos com configurações diferentes e veja qual funciona melhor.
4. Análise / Avaliação
Avaliação de métricas
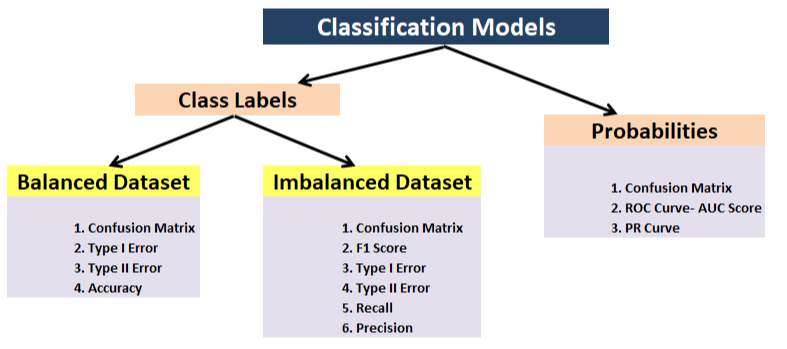
Classificação – Acurácia, precisão, recall, F1, matriz de confusão, precisão média (detecção de objeto);
Regressão – MSE, MAE, R ^ 2;
Métrica baseada em tarefas – por exemplo, para um carro que dirige sozinho, você pode querer saber o número de desengates.
Engenharia de atributos
Custo de treinamento / inferência.
5. Modelo de Serviço (implantação de um modelo)
Coloque o modelo em produção;
Ferramentas que você pode usar: TensorFlow Servinf, PyTorch Serving, Google AI Platform, Sagemaker;
MLOps: onde a engenharia de software encontra o aprendizado de máquina, basicamente toda a tecnologia necessária em torno de um modelo de aprendizado de máquina para que funcione na produção.
Usar o modelo para fazer previsões;
Reavaliar.
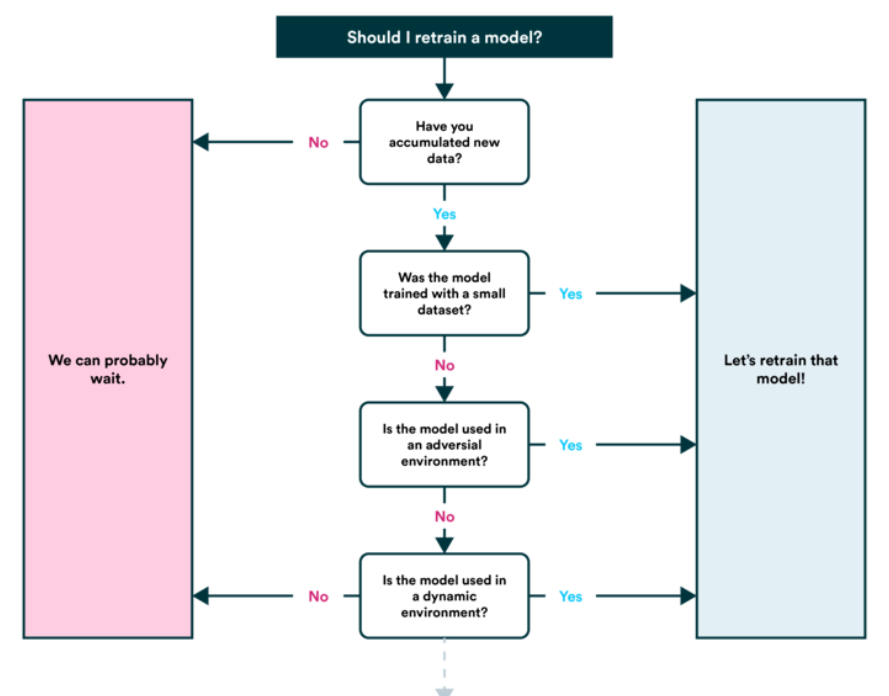
6. Modelo de retreinamento
O modelo ainda é válido para novas cargas de trabalho?
Veja o desempenho do modelo após a veiculação (ou antes da veiculação) com base em várias métricas de avaliação e reveja as etapas acima conforme necessário. Lembre-se de que o aprendizado de máquina é muito experimental, então é aqui que você deverá rastrear seus dados e experimentos;
Você também verá que as previsões do seu modelo começam a “envelhecer” ou “flutuar”, como quando as fontes de dados mudam ou atualizam (novo hardware, etc.). É quando você deverá retreiná-lo.
O Insight preparou uma lista com 10 repositórios para ajudar você no desenvolvimento de suas tarefas em Ciência de Dados. O Github é uma plataforma gratuita que hospeda código fonte por meio do controle de versão (o Git) e disponibiliza diversos repositórios abertos feitos por interessados na área.
A área de estudos em Ciência de Dados é muito ampla e no GitHub existem diversos repositórios com projetos muito úteis a quem se interessa por Ciência de Dados. E para tornar sua pesquisa mais fácil, nós separamos alguns para você. Confira:
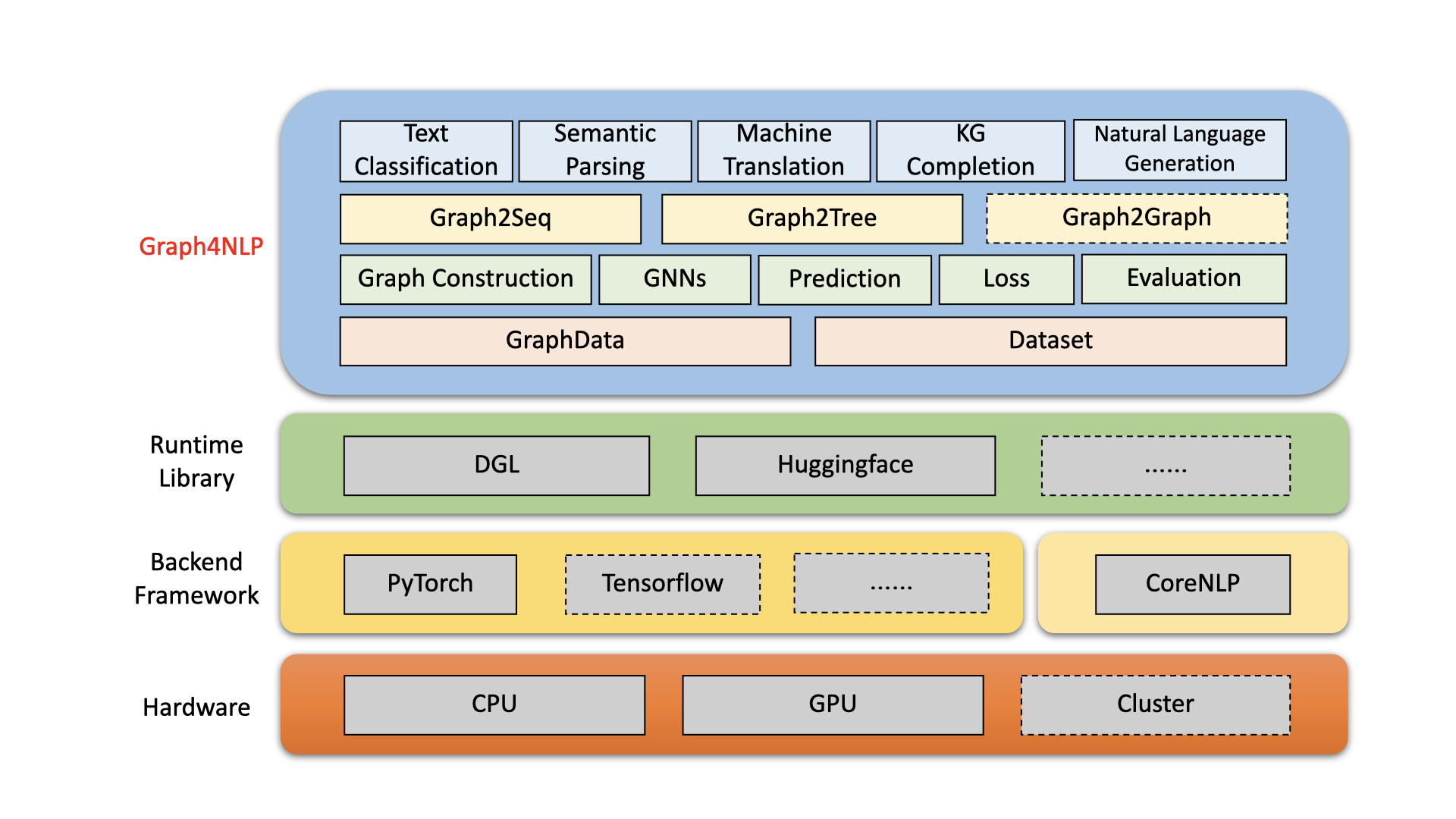
Esta é uma biblioteca fácil de usar para P&D na interseção de Aprendizado Profundo em Gráficos e Processamento de Linguagem Natural. Ele fornece implementações completas de modelos de última geração para cientistas de dados e também interfaces flexíveis para construir modelos personalizados para pesquisadores e desenvolvedores com suporte de pipeline completo.
Construído sobre bibliotecas com tempo de execução altamente otimizadas, incluindo DGL, esta biblioteca tem alta eficiência de execução e alta extensibilidade. Sua arquitetura é mostrada na figura a seguir, onde caixas com linhas tracejadas representam os recursos em desenvolvimento que consistem em quatro camadas diferentes:
Este é um framework de Machine Learning de código aberto para automatizar conversas baseadas em texto e voz. Com o Rasa, você pode criar assistentes contextuais para diversas plataformas:
Facebook Messenger;
Folga;
Hangouts do Google;
Equipes Webex;
Microsoft Bot Framework;
Rocket.Chat;
Mattermost;
Telegrama;
Twilio.
E também em assistentes de voz como: Alexa Skills e ações do Google Home.
Rasa ajuda a criar assistentes contextuais capazes de ter conversas em camadas com muitas idas e vindas. Para que um humano tenha uma troca significativa com um assistente virtual, este precisa ser capaz de usar o contexto para desenvolver coisas que foram discutidas anteriormente. O Rasa permite que você crie assistentes que podem fazer isso de uma forma escalonável.
Merlion é uma biblioteca Python para inteligência em séries temporais. Ela fornece uma estrutura de Machine Learning de ponta a ponta que inclui carregamento e transformação de dados, construção de modelos de treinamento, saídas de modelo de pós-processamento e avaliação de desempenho do modelo. Além disso, oferece suporte a várias tarefas de aprendizagem em séries temporais, incluindo previsão, detecção de anomalias e detecção de ponto de mudança para séries temporais univariadas e multivariadas.
Esta biblioteca tem como objetivo fornecer aos engenheiros e pesquisadores uma solução completa para desenvolver rapidamente modelos para suas necessidades específicas em séries temporais e compará-los em vários datasets.
As principais características do Merlion são: carregamento e benchmarking de dados padronizados e facilidades extensíveis para uma ampla gama de datasets de previsão e detecção de anomalias.
NitroFE é um mecanismo de engenharia de features do Python que fornece uma variedade de módulos projetados para salvar internamente valores com dependência do passado para fornecer cálculos contínuos.
Os atributos de indicadores, janelas e médias móveis dependem dos valores anteriores para cálculo. Por exemplo, uma janela móvel de tamanho 4 depende dos 4 valores anteriores. Embora a criação de tais atributos durante o treinamento seja bastante simples, levá-los para a produção se torna um desafio, pois exigiria que alguém salvasse externamente os valores anteriores e implementasse a lógica. A criação de indicadores torna-se ainda mais complexa, pois dependem de vários outros componentes de janela de tamanhos diferentes.
O NitroFE lida internamente com o salvamento de valores com dependência do passado e torna a criação de recursos descomplicada. Basta usar first_fit = True para seu ajuste inicial.
Em estatística, uma média móvel é um cálculo para analisar pontos de dados criando uma série de médias de diferentes subconjuntos do dataset. O NitroFE oferece uma variedade de tipos de médias móveis para você utilizar.
O Aim registra suas execuções de treinamento, possui uma bela interface para compará-los e uma API para consultá-los programaticamente. Essa é uma ferramenta de rastreamento de experimentos de IA auto-hospedada e de código aberto. Útil para inspecionar profundamente centenas de execuções de treinamento sensíveis a hiperparâmetros de uma só vez.
O SDK do Aim registra quantas métricas e parâmetros forem necessários para as execuções de treinamento e avaliação. Os usuários do Aim monitoram milhares de execuções de treinamento e, às vezes, mais de 100 métricas por execução com muitas etapas.
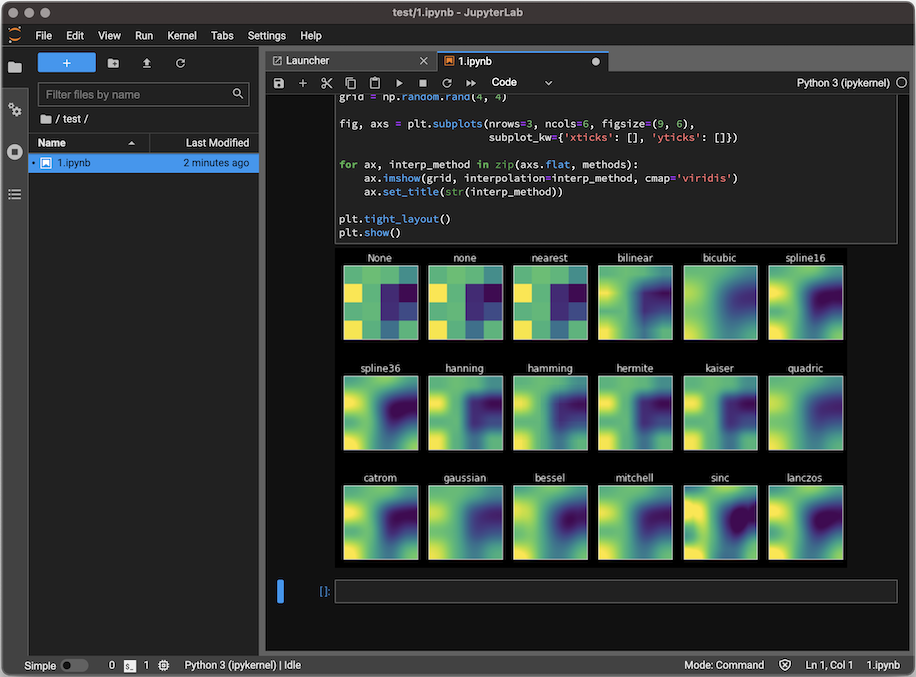
O JupyterLab é a interface da próxima geração de usuários do Project Jupyter, oferecendo todos os blocos de construção familiares do Jupyter Notebook clássico (notebook, terminal, editor de texto, navegador de arquivos, saídas ricas, etc.) em uma interface de usuário flexível e poderosa. O JupyterLab eventualmente substituirá o Jupyter Notebook clássico.
Você pode organizar vários documentos e atividades lado a lado na área de trabalho usando guias e divisores. Documentos e atividades se integram, permitindo novos fluxos de trabalho para computação interativa, por exemplo:
Os consoles de código fornecem rascunhos temporários para a execução de código de forma interativa, com suporte total para uma saída valiosa. Um console de código pode ser vinculado a um kernel do notebook como um log de computação do notebook, por exemplo.
Documentos baseados em kernel permitem que o código em qualquer arquivo de texto (Markdown, Python, R, LaTeX, etc.) seja executado interativamente em qualquer kernel Jupyter.
As saídas das células do notebook podem ser espelhadas em sua própria guia, lado a lado com o notebook, permitindo painéis simples com controles interativos apoiados por um kernel.
Múltiplas visualizações de documentos com diferentes editores ou visualizadores permitem a edição ao vivo de documentos refletidos em outros visualizadores. Por exemplo, é fácil ter uma visualização ao vivo de Markdown, valores separados por delimitador ou documentos Vega / Vega-Lite.
A interface também oferece um modelo unificado para visualizar e manipular formatos de dados. O JupyterLab compreende muitos formatos de arquivo (imagens, CSV, JSON, Markdown, PDF, Vega, Vega-Lite, etc.) e também pode exibir uma saída rica do kernel nesses formatos. Consulte Arquivos e formatos de saída para obter mais informações.
River é uma biblioteca Python para Machine Learning (ML) on-line. É o resultado da fusão entre o creme e o scikit-multiflow. O objetivo do River é ser a biblioteca ideal para fazer ML em dados de streaming.
O Machine Learning geralmente é feito em uma configuração de batch, em que um modelo é ajustado a um dataset de uma só vez. Isso resulta em um modelo estático que precisa ser retreinado para aprender com os novos dados. Em muitos casos, isso não é eficiente e geralmente resulta em um problema técnico considerável. Na verdade, se você estiver usando um modelo em batch, precisará pensar em manter um conjunto de treinamento, monitorar o desempenho em tempo real, retreinar o modelo, etc.
Com o River, a abordagem é aprender continuamente com um fluxo de dados. Isso significa que o modelo processa uma observação por vez e pode, portanto, ser atualizado em tempo real. Permitindo assim, aprender com grandes datasets que não cabem na memória principal.
Flash é uma coleção de tarefas para prototipagem rápida, definição de linha de base e ajuste fino de modelos de Deep Learning escaláveis, baseados noPyTorch Lightning.
Quer você seja novo no Deep Learning ou um pesquisador experiente, o Flash oferece uma experiência perfeita, desde experimentos básicos até pesquisas de ponta. Ele permite que você construa modelos sem ser sobrecarregado por todos os detalhes e, em seguida, substitua e experimente o Lightning para obter total flexibilidade.
Com o Flash, você pode criar sua própria imagem ou classificador de texto em algumas linhas de código, sem necessidade de matemática. Atualmente ele suporta: classificação Imagem, incorporação Imagem, classificação tabular, classificação de texto, sumarização, tradução entre outras.
As tarefas do Flash contêm todas as informações relevantes para resolver sua tarefa como: o número de rótulos de classe que você deseja prever, o número de colunas em seu dataset, bem como detalhes sobre a arquitetura do modelo usada, como função de perda, otimizadores, etc.
ParlAI (pronuncia-se “par-lay”) é uma estrutura Python para compartilhar, treinar e testar modelos de diálogo, desde bate-papos de domínio aberto a diálogos orientados a tarefas e respostas visuais de perguntas.
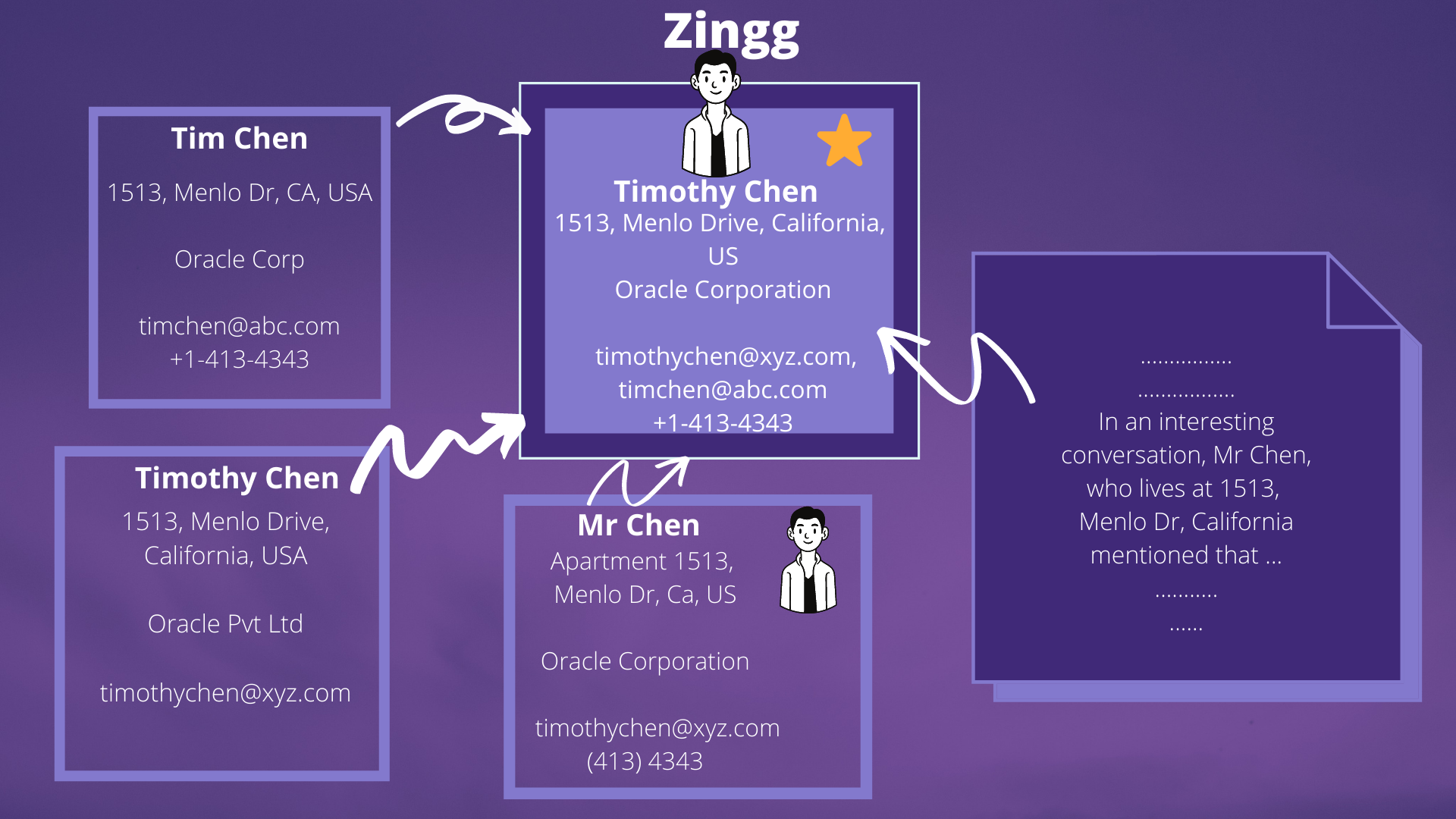
Os dados do mundo real contêm vários registros pertencentes ao mesmo cliente. Esses registros podem estar em um único sistema ou em vários e possuírem variações nos campos, o que torna difícil combiná-los, especialmente com volumes de dados crescentes. Isso prejudica a análise do cliente – estabelecer valor vitalício, programas de fidelidade ou canais de marketing é impossível quando os dados básicos não estão vinculados.
Nenhum algoritmo de IA para segmentação pode produzir resultados corretos quando há várias cópias do mesmo cliente escondidas nos dados. Nenhum data warehouse pode cumprir sua promessa se as tabelas de dimensão tiverem duplicatas.
Com uma pilha de dados e DataOps modernos, estabelecemos padrões para E e L em ELT para a construção de data warehouses, datalakes e deltalakes. No entanto, o T – preparar os dados para análises ainda precisa de muito esforço. Ferramentas modernas como DBT estão lidando com isso de forma ativa e bem-sucedida. O que também é necessário é uma maneira rápida e escalável de construir a única fonte de verdade das principais entidades de negócios pós-extração e pré ou pós-carregamento.
Com o Zingg, o engenheiro analítico e o cientista de dados podem integrar rapidamente silos de dados e construir visualizações unificadas em escala!
Obrigado por conferir nossa lista, esperamos que isso tenha contribuído para o conhecimento e crescimento com um cientista de dados!
O Insight e o laboratório ÍRIS estão cominscrições abertas para bolsistas desenvolvedores ou pesquisadores. Venha fazer parte do nosso time e contribuir com pesquisas acadêmicas e tecnologias de ponta aplicadas aos problemas da sociedade e das organizações.
Vagas para bolsistas graduados e graduandos:
Desenvolvedor Back End;
Pesquisador em Ciência de Dados.
Habilidades:
Desenvolvedor Back End:
Java (Spring Boot)
Mongo
Pesquisador em Ciência de dados:
Python
Pandas
Numpy
Scikit Learn
Cursado alguma disciplina de Aprendizado de Máquina
Modalidade de Contratação
Alunos de graduação: bolsa FUNCAP de R$ 800,00 com uma carga horária de 20h semanais.
Graduados, valor da bolsa a combinar com carga horária até 40h semanais.
Etapas da seleção
Envio do formulário, até:
26/08
Resultado da análise de currículo e histórico
27/08
Entrevistas
30/08
Resultado final
31/08
Formulário de inscrição
Acesse o formulário de inscrição para registrar seus dados, enviar seu currículo e histórico escolar. Fique atento às datas e ao seu e-mail.
Nós usamos cookies para melhorar sua experiência de navegação. Ao navegar no site, você concorda com a política de monitoramento de cookies. Se você concorda, clique em OK. Para ter mais informações sobre como isso é feito, acesse nosso Aviso de Privacidade.OKAviso de Privacidade