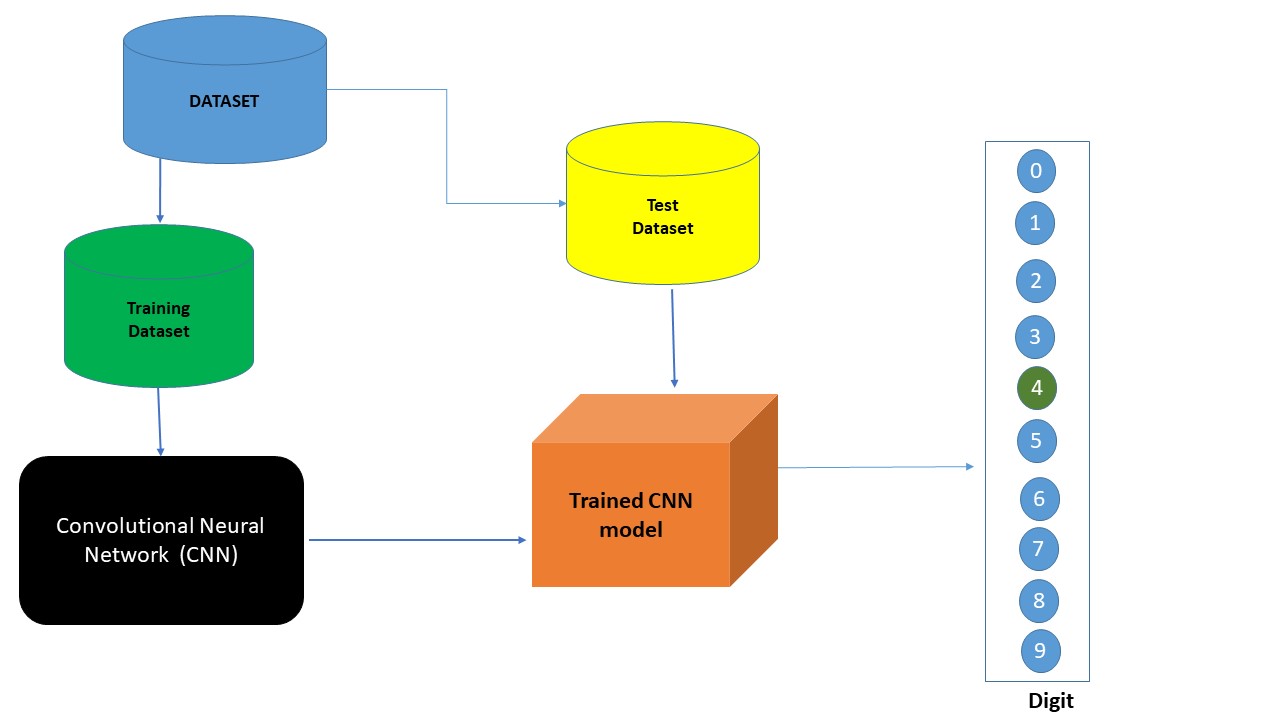
PLN ou Processamento de Linguagem Natural é a forma como as máquinas entendem e lidam com as linguagens humanas. Esta técnica lida com dados não estruturados de texto e embora seja difícil de dominá-la é fácil de entender seus conceitos.
Cientes disso, devemos entender que a disponibilidade e geração de dados são complexidades envolvidas, em geral, com qualquer tipo de caso de uso de Machine Learning (ML). Mas o PLN é o campo onde esse problema é relativamente menos pronunciado, pois há muitos dados de texto ao nosso redor. Os e-mails que escrevemos, os comentários que postamos, os blogs que escrevemos são alguns exemplos.
Tipos:
1) Reconhecimento de entidade nomeada
O processo de extração de entidades de nomeadas no texto, nome de pessoas, países, organizações, extrai informações úteis que podem ser usadas para vários fins como: classificação, recomendação, análise de sentimento, entre outros.
Um chatbot é o exemplo de uso mais comum. A consulta do usuário é entendida por meio das entidades no texto e respondida de acordo com elas.
2) Resumo do texto
É onde os conceitos-chave do texto são extraídos e o resumo parafraseado é construído em torno dele. Isso pode ser útil em resultados de pesquisas extensos.
3) Tradução
Conversão de texto de uma linguagem para outra. O tradutor do Google é o exemplo mais comum que temos.
4) Fala em texto
Converte voz em dados de texto, sendo o exemplo mais comum os assistentes em nossos smartphones.
5) NLU
Natural Language Understanding é uma forma de entender as palavras e frases no que diz respeito ao contexto. Eles são úteis na análise de sentimento dos comentários de usuários e consumidores. Modelos NLU são comumente usados na criação de chatbot.
6) NLG
Natural Language Generation vai além do processamento da máquina ou da compreensão do texto. Essa é a capacidade das máquinas de escrever conteúdo por si mesmas. Uma rede profunda, usando Transformers GTP-3, escreveu este artigo.
Iniciando
Os insights sobre como o Machine Learning lida com dados não estruturados de texto são apresentados por meio de um exemplo básico de classificação de texto.
Entrada:
Uma coluna de ‘texto’ com comentários de revisão por usuário. Uma coluna de ‘rótulo’ com um sinalizador para indicar se é um comentário positivo ou negativo.
Saída:
A tarefa é classificar os comentários com base no sentimento como positivos ou negativos.
Etapas de pré-processamento
Um pré-processamento será feito para transformar os dados em algoritmos de ML. Como o texto não pode ser tratado diretamente por máquinas, ele é convertido em números. Dessa forma, os dados não estruturados são convertidos em dados estruturados.
NLTK é uma biblioteca Python que pode ajudar você nos casos de uso de PLN e atende muito bem às necessidades de pré-processamento.
1) Remoção de palavras irrelevantes
Palavras irrelevantes ocorrem com frequência e não acrescentam muito significado ao texto. Os mecanismos de pesquisa também são programados para ignorar essas palavras. Podemos citar como exemplo as palavras: de, o, isso, tem, seu, o quê, etc.
A remoção dessas palavras ajuda o código a se concentrar nas principais palavras-chave do texto que adicionam mais contexto.
Código de explicação:
import nltk nltk.download(‘stopwords’) from nltk.corpus import stopwords stop = stopwords.words(‘english’) print(stop)
Saída:
[‘i’, ‘me’, ‘my’, ‘myself’, ‘we’, ‘our’, ‘ours’, ‘ourselves’, ‘you’, “you’re”, “you’ve”, “you’ll”, “you’d”, ‘your’, ‘yours’,…]
Código de implementação:
Aplicando a remoção de palavras irrelevantes a um data frame do Pandas com uma coluna de ‘texto’.
input_df[‘text’] = input_df[‘text’].apply(lambda x: “ “.join(x for x in x.split() if x not in stop))
2) Remoção de emojis e caracteres especiais
Os comentários do usuário são carregados de emojis e caracteres especiais. Eles são representados como caracteres Unicode no texto, denotados como U +, variando de U + 0000 a U + 10FFFF.
import re
def remove_emoji(text):
emoji_pattern = re.compile("["
u"U0001F600-U0001F64F" # emoticons
u"U0001F300-U0001F5FF" # symbols & pictographs
u"U0001F680-U0001F6FF" # transport & map symbols
u"U0001F1E0-U0001F1FF" # flags (iOS)
u"U0001F1F2-U0001F1F4" # Macau flag
u"U0001F1E6-U0001F1FF" # flags
u"U0001F600-U0001F64F"
u"U00002702-U000027B0"
u"U000024C2-U0001F251"
u"U0001f926-U0001f937"
u"U0001F1F2"
u"U0001F1F4"
u"U0001F620"
u"u200d"
u"u2640-u2642"
"]+", flags=re.UNICODE)
return emoji_pattern.sub(r”, text)
sample_text= ‘That was very funny ?. Have a lovely day ? ‘
remove_emoji(sample_text)
Saída:
‘That was very funny . Have a lovely day ‘
Código de implementação:
input_df[‘text’] = input_df[‘text’].apply(lambda x: remove_emoji(x))
3) Flexão
Flexão é a modificação de uma palavra para expressar diferentes categorias gramaticais como tempo verbal, voz, aspecto, pessoa, número, gênero e humor. Por exemplo, as derivações de ‘venha’ são ‘veio’, ‘vem’. Para obter o melhor resultado, as flexões de uma palavra devem ser tratadas da mesma maneira. Para lidar com isso usamos a lematização.
A lematização resolve as palavras em sua forma de dicionário (conhecida como lema), para a qual requer dicionários detalhados nos quais o algoritmo pode pesquisar e vincular palavras aos lemas correspondentes.
Por exemplo, as palavras “correr”, “corre” e “correu” são todas formas da palavra “correr”, portanto “correr” é o lema de todas as palavras anteriores.
a) Stemming
Stemming é uma abordagem baseada em regras que converte as palavras em sua palavra raiz (radical) para remover a flexão sem se preocupar com o contexto da palavra na frase. Isso é usado quando o significado da palavra não é importante. A palavra raiz pode ser uma palavra sem sentido em si mesma.
Código de explicação:
from nltk.stem import PorterStemmer</span> <span style="font-weight: 400;" data-mce-style="font-weight: 400;">porter = PorterStemmer()
Amostra 1:
print(porter.stem('trembling'),
porter.stem('tremble'),
porter.stem('trembly'))
Saída:
trembl trembl trembl
Amostra 2:
print(porter.stem('study'),
porter.stem('studying'),
porter.stem('studies'))
Saída:
studi studi studi
Código de implementação
def stemming_text(text): stem_words = [porter.stem(w) for w in w_tokenizer.tokenize(text)] return ‘ ‘.join(stem_words) input_df[‘text’] = input_df[‘text’].apply(lambda x: stemming_text(x))
b) Lematização
A lematização, ao contrário de Stemming, reduz as palavras flexionadas adequadamente, garantindo que a palavra raiz (lema) pertence ao idioma. Embora a lematização seja mais lenta em comparação com a Stemming, ela considera o contexto da palavra levando em consideração a palavra anterior, o que resulta em melhor precisão.
Código de explicação:
w_tokenizer = nltk.tokenize.WhitespaceTokenizer()
lemmatizer = nltk.stem.WordNetLemmatizer()
def lemmatize_text(text):
lemma_words = [lemmatizer.lemmatize(w) for w in w_tokenizer.tokenize(text)]
return ‘ ‘.join(lemma_words)
print(lemmatize_text('study'),
lemmatize_text('studying') ,
lemmatize_text('studies'))
Saída:
study studying study
print(lemmatize_text('trembling'),
lemmatize_text('tremble') ,
lemmatize_text('trembly'))
Saída:
trembling tremble trembly
Código de implementação:
input_df[‘text’] = input_df[‘text’].apply(lemmatize_text)
4) Vetorizador
Esta é a etapa em que as palavras são convertidas em números, que podem ser processados pelos algoritmos. Esses números resultantes estão na forma de vetores, daí o nome.
1) Modelo Bag of words
Este é o mais básico dos vetorizadores. O vetor formado contém palavras no texto e sua frequência. É como se as palavras fossem colocadas em um saco. A ordem das palavras não é mantida.
Código de explicação:
from sklearn.feature_extraction.text import CountVectorizer
bagOwords = CountVectorizer()
print(bagOwords.fit_transform(text).toarray())
print('Features:', bagOwords.get_feature_names())
Entrada:
text = [“I like the product very much. The quality is very good.”,
“The product is very very good”,
“Broken product delivered”,
“The product is good, but overpriced product”,
“The product is not good”]
Saída:
array([[0, 0, 0, 1, 1, 1, 1, 0, 0, 1, 1, 2, 2],
[0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 1, 1],
[1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0],
[0, 1, 0, 1, 1, 0, 0, 0, 1, 2, 0, 1, 0],
[0, 0, 0, 1, 1, 0, 0, 1, 0, 1, 0, 1, 0]])
Features: [‘broken’, ‘but’, ‘delivered’, ‘good’, ‘is’, ‘like’, ‘much’, ‘not’, ‘overpriced’, ‘product’, ‘quality’, ‘the’, ‘very’]
Os vetores dos textos 2 e 5 (ao contrário do que se espera), por serem de sentidos opostos, não diferem tanto. A matriz retornada é esparsa.
2) n-gramas
Ao contrário da abordagem do saco de palavras, a abordagem de n-gram depende da ordem das palavras para derivar seu contexto. O n-gram é uma sequência contígua de “n” itens em um texto, portanto, o conjunto de recursos criado com o recurso n-grams terá um número n de palavras consecutivas como recursos. O valor para “n” pode ser fornecido como um intervalo.
Código de explicação:
count_vec = CountVectorizer(analyzer='word', ngram_range=(1, 2))
print('Features:', count_vec.get_feature_names())
print(count_vec.fit_transform(text).toarray())
Saída:
[[0 0 0 0 0 1 0 1 0 0 1 1 1 1 1 0 0 0 0 1 0 0 1 1 1 2 1 1 2 1 1]
[0 0 0 0 0 1 0 1 0 0 1 0 0 0 0 0 0 0 0 1 0 1 0 0 0 1 1 0 1 1 0]
[1 1 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 0]
[0 0 1 1 0 1 1 1 1 0 0 0 0 0 0 0 0 1 1 2 0 1 0 0 0 1 1 0 0 0 0]
[0 0 0 0 0 1 0 1 0 1 0 0 0 0 0 1 1 0 0 1 0 1 0 0 0 1 1 0 0 0 0]]
Features: [‘broken’, ‘broken product’, ‘but’, ‘but overpriced’, ‘delivered’, ‘good‘, ‘good but’, ‘is’, ‘is good’, ‘is not’, ‘is very’, ‘like’, ‘like the’, ‘much’, ‘much the’, ‘not’, ‘not good’, ‘overpriced’, ‘overpriced product’, ‘product’, ‘product delivered’, ‘product is’, ‘product very’, ‘quality’, ‘quality is’, ‘the’, ‘the product’, ‘the quality’, ‘very’, ‘very good’, ‘very much’]
3) TF-IDF
Só porque uma palavra aparece com alta frequência não significa que a palavra acrescenta um efeito significativo sobre o sentimento que procuramos. A palavra pode ser comum a todos os textos de amostra. Por exemplo, a palavra ‘product’ em nossa amostra é redundante e não fornece muitas informações relacionadas ao sentimento. Isso apenas aumenta a duração do recurso.
Frequência do termo (TF) – é a frequência das palavras em um texto de amostra.
Frequência inversa do documento (IDF) – destaca a frequência das palavras em outros textos de amostra. Os recursos são raros ou comuns nos textos de exemplo é a principal preocupação aqui.
Quando usamos ambos os TF-IDF juntos (TF * IDF), as palavras de alta frequência em um texto de exemplo que tem baixa ocorrência em outros textos de exemplo recebem maior importância.
Código de explicação
from sklearn.feature_extraction.text import TfidfVectorizer
tf_idf_vec = TfidfVectorizer(use_idf=True,
smooth_idf=False,
ngram_range=(1,1))
print(tf_idf_vec.fit_transform(text).toarray())
print('Features:', tf_idf_vec.get_feature_names())
Saída


No terceiro texto de exemplo, as palavras de valores ‘broken‘ e ‘delivered‘ são raras em todos os textos e recebem pontuação mais alta do que ‘product‘, que é uma palavra recorrente.
Código de implementação
tfidf_vec = TfidfVectorizer(use_idf=True)
tfidf_vec.fit(input_df[‘text’])
tfidf_result = tfidf_vec.transform(input_df[‘text’])
5) Desequilíbrio de classe
Geralmente, esse tipo de cenário terá um desequilíbrio de classe. Os dados de texto incluíam mais casos de sentimento positivo do que negativo. A maneira mais simples de lidar com o desequilíbrio de classe é aumentando os dados com cópias exatas da classe minoritária (neste caso, os cenários de sentimento negativo). Essa técnica é chamada de sobreamostragem.
Algoritmo de Machine Learning
Após a conclusão das etapas de processamento, os dados estão prontos para serem passados para um algoritmo de ML para ajuste e previsão. Este é um processo iterativo no qual um algoritmo adequado é escolhido e o ajuste do hiperparâmetro é feito.
Um ponto a ser observado aqui é que, aparentemente, como qualquer outro problema de ML, as etapas de pré-processamento devem ser tratadas após a divisão de treinamento e teste.
Código de implementação
from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import f1_score rnd_mdl = RandomForestClassifier() rnd_mdl.fit(tfidf_result, input_df[‘label’]) #Using the fitted model to predict from the test data #test_df is the test data and tfidf_result_test is the preprocessed test text data output_test_pred = rnd_mdl.predict(tfidf_result_test) #finding f1 score for the generated model test_f1_score = f1_score(test_df[‘label’], output_test_pred)
Biblioteca pré-construída
Há uma biblioteca pré-construída em NLTK que pontua os dados de texto com base no sentimento. Ele não precisa dessas etapas de pré-processamento. É denominado nltk.sentiment.SentimentAnalyzer.
Finalizando
Existem muitos modelos avançados de Deep Learning pré-treinados disponíveis para PLN. O pré-processamento envolvido, ao usar essas redes profundas, varia consideravelmente da abordagem de ML fornecida aqui.
Esta é uma introdução simples ao interessante mundo da PLN! É um vasto espaço em constante evolução!
Traduzido de analyticsvidhya.com