Uma dica de ouro! Um dos melhores livros prático sobre Machine Learning. Seja para você, iniciante na área e que precisa de um guia, ou para quem já atua e precisa de um complemento.
MÃOS À OBRA: APRENDIZADO DE MÁQUINA COM SCIKIT-LEARN & TENSORFLOW. Conceitos, ferramentas e técnicas para a construção de sistemas inteligentes de Aurélien Géron é um livro com ótima avaliação pelos leitores.
De maneira prática, o livro mostra como utilizar ferramentas simples e eficientes para implementar programas capazes de aprender com dados. Utilizando exemplos concretos, uma teoria mínima e duas estruturas Python prontas para produção ― Scikit-Learn e TensorFlow ― o autor Aurélien Géron ajuda você a adquirir uma compreensão intuitiva dos conceitos e ferramentas para a construção de sistemas inteligentes.
Você aprenderá uma variedade de técnicas, desde de uma regressão linear simples até redes neurais profundas. Com exercícios em cada capítulo para ajudá-lo a aplicar o que aprendeu, você só precisa ter experiência em programação para começar.
Segundo Pete Warden, líder mobile do TensorFlow, o livro é uma ótima introdução à teoria e prática na resolução de problemas com redes neurais abrangendo os pontos-chave necessários para entender novas pesquisas.
Na edição atualizada o livro traz exemplos concretos, teoria mínima e três estruturas Python prontas para produção – scikit-learn, Keras e TensorFlow – para ajudá-lo a obter uma compreensão intuitiva dos conceitos e ferramentas para a construção de sistemas inteligentes.
Curiosidades sobre o autor: Aurélien Géron ensinou seus 3 filhos a contar em binário com os dedos (até 1023), ele estudou microbiologia e genética evolutiva antes de entrar na engenharia de software, e seu paraquedas não abriu no segundo salto.
Na era da informação na qual vivemos, ouve-se muito sobre o valor dos dados que geramos cotidianamente e, por consequência, sobre a demanda de profissionais criada para realizar a análise dos mesmos. Isso posto, podemos então dizer seguramente que a atuação tendência do momento é a de Cientista de Dados. Mas essa não é a única profissão com alta demanda (e boas remunerações) por aí: você já ouviu falar sobre o Engenheiro de Dados? Não? Então segue a leitura, neste post nós vamos te contar tudo sobre essa carreira, quais atividades são desempenhadas nela e quais as habilidades necessárias para se tornar um bom Engenheiro de Dados.
Mas afinal, o que é um Engenheiro de Dados?
Antes de entrarmos em uma definição é necessário termos em mente que, nos times modernos de Ciência de Dados, é cada vez mais comum encontrar papéis bem definidos a fim de facilitar todo o fluxo de trabalho na empresa. Nesses times existem pelo menos três papéis distintos:
O Engenheiro de Dados, responsável por assegurar, através de linguagens de programação, que os dados sejam limpos, confiáveis e disponíveis para acesso em alta performance sempre que necessário;
O Analista de Dados, que utiliza ferramentas de business intelligence, planilhas e linguagens de programação para categorizar e descrever os dados já existentes;
O Cientista de Dados, que faz uso dos dados para realizar predições e extração de conhecimento desses dados.
Ou seja, podemos definir o Engenheiro de Dados como a pessoa que é responsável por preparar os dados para uso analítico e operacional, gerenciando os processos de ETL (Extract, Transform, Load), pipelines de execução e o fluxo de trabalho dos dados.
Qual a atuação do Engenheiro de Dados?
Embora o Engenheiro de Dados tenha suas atribuições bem definidas, ele trabalha em conjunto com os Analistas e Cientistas de Dados. As principais atividades de um Engenheiro de Dados envolvem:
Construir e manter os sistemas de pipelines dos dados da empresa
O pipeline dos dados abrange os processos pelos quais os dados passam na empresa, definindo para onde e qual setor eles irão. O Engenheiro de Dados é responsável pela criação desses pipelines, além de mantê-los funcionando sempre da melhor forma possível. O engenheiro deve entender quais as melhores ferramentas a serem utilizadas, bem como conhecer as tecnologias e frameworks existentes, combinando-as para facilitar o processo de pipeline no negócio da empresa.
Limpar e organizar os dados de forma útil
Um Engenheiro de Dados assegura que os dados estejam limpos, organizados, confiáveis e preparados para qualquer caso de uso. A organização dos dados é uma das principais atividades do engenheiro e envolve tarefas como transformar dados bagunçados e brutos em dados realmente úteis. O engenheiro também é responsável por responder questões como: “o quão bons são esses conjuntos de dados?”, “o quão relevantes eles são para o objetivo procurado?” e “existe uma fonte de dados melhor?”, de modo que seu trabalho possa auxiliar o Cientista de Dados no processo de extração de conhecimento.
O que devo saber para me tornar um Engenheiro de Dados?
Para se tornar um Engenheiro de Dados, seu conhecimento deve abranger muitas áreas como: formatação de arquivos, processamento de dados em streaming e em batches, SQL, armazenamento de dados, gerenciamento de clusters, banco de dados transacionais, frameworks para web, visualização de dados e, até mesmo, machine learning.
Como observado, a lista de conhecimentos requeridos pode ser grande, mas você já tem um bom ponto de partida caso possua algumas dessas skills:
Conhecimentos de Linux e uso de linhas de comando;
Experiência com linguagens de programação como Java, Python e Scala;
Conhecimentos de SQL;
Entendimento de como funcionam sistemas distribuídos em geral e quais as principais diferenças em relação a armazenamentos tradicionais e sistemas de processamento;
Profundo entendimento dos ecossistemas existentes, incluindo ingestão (Kafka, Kinesis), frameworks de processamento (Spark, Flink), e engines de armazenamento (HDFS, Hbase, Kudu, etc);
Conhecimentos de como processar e acessar dados.
E é isso, caro leitor. Esperamos que este post tenha sido útil para introduzir um pouco dessa profissão tão fascinante. Caso queira ler um pouco mais a respeito, este artigo explica muito bem a diferença entre o engenheiro e o cientista de dados.
Desde o final do milênio passado, uma palavra relativamente desconhecida começou a ser propagada: “streaming”. Timidamente no início e geralmente em áreas mais técnicas, foi gradualmente emergindo até se tornar onipresente.
De plataformas de áudio (Spotify, Deezer, Apple Music, YouTube Music, Amazon Music,Tidal, entre outras) e de vídeo (Youtube, Netflix, Vimeo, DailyMotion, Twitch, entre outras) a aplicações mais específicas, o streaming passou a ser uma palavra do cotidiano dos devs.
Geralmente, o termo vem acompanhado de outro já bem conhecido: Big Data, o qual podemos entender como conjuntos de dados (dataset) tão grandes que não podem ser processados e gerenciados utilizando soluções clássicas como sistemas de banco de dados relacionais (SGBD). Podemos ter streaming de dados fora do contexto de Big Data, porém é bem comum essas palavras virem em um mesmo contexto.
Neste instante, o desenvolvedor já quer fazer um “hello world” e já pergunta: “qual o melhor framework de streaming?” (falar no melhor é quase sempre generalista e enviesado, o termo “mais adequado” é mais realista, opinião do autor). Vamos entender o que é streaming de dados e o que podemos entender como “tempo real”.
Streaming de dados
Para uma melhor concepção do que é streaming de dados, primeiro vamos entender o que é processamento de dados em batch (lote em português ou, um termo mais antigo, “batelada”).
As tarefas computacionais geralmente são chamadas de jobs e podem executar em processos ou threads. Os que podem ser executados sem a interação do usuário final ou ser agendados para execução são chamados de batch jobs. Um exemplo é um programa que lê um arquivo grande e gera um relatório.
Frameworks
Na era do Big Data, surgiram vários modelos de programação e frameworks capazes de executar jobs em batch de forma otimizada e distribuída. Um deles é o modelo de programação MapReduce que foi introduzido e utilizado inicialmente pela Google como um framework que possui três componentes principais: uma engine de execução MapReduce, um sistema de arquivo distribuído chamado Google File System (GFS) e um banco de dados NoSQL chamado BigTable.
Podemos citar vários outros frameworks que possuem capacidade de processamento de dados em larga escala, em paralelo e com tolerância a falhas como: Apache Hadoop, Apache Spark, Apache Beam e Apache Flink (falaremos mais dele adiante). Frameworks que executam processamento em batch geralmente são utilizados para ETL (Extract Transform Load).
Processamento de datasets em forma de streaming
Uma outra forma de processar datasets é em forma de streaming. Aqui, já deixamos uma dica importante: streaming não é melhor que batch, são duas formas diferentes de processar dados e cada uma delas possui suas particularidades e aplicações.
Então, sem mais delongas, o que é um processamento de dados em streaming? De acordo com o excelente (e super indicado) livro “Streaming Systems: The What, Where, When, and How of Large-Scale Data Processing”, podemos definir streaming como “um tipo de engine de processamento de dados projetado para tratar datasets infinitos”.
A primeira coisa a se ter em mente é que os dados virão infinitamente (unbounded), diferente do processamento em batch que é finito, e não há como garantir a ordem em que os mesmos chegam. Para isso existe uma série de estratégias (ou heurísticas) que tenta mitigar tais questões e cada uma delas com seus pontos fortes e fracos. Como diz o ditado: “There is no free lunch”!
Quando tratamos de datasets, podemos falar de duas estruturas importantes: tabelas, como uma visão específica do dado em um ponto específico do tempo, como acontece nos SGBDs tradicionais, e streams, como uma visão elemento a elemento durante a evolução de um dataset ao longo do tempo.
Dois eixos de funcionamento: sources e sinks
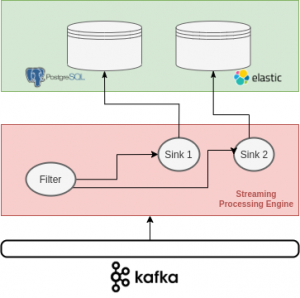
O dataset no processamento de streams funciona com duas pontas: sources e sinks. O source representa uma conexão de entrada e o sink uma de saída no seu streaming. Para clarear, podemos fazer uma analogia bem simples: pensem em uma caixa d’água que é enchida por meio de uma ligação de canos da companhia de água da sua cidade. Essa caixa d’água dá vazão para as torneiras e chuveiros da casa por meio da ligação hidráulica de sua residência. Nessa abstração, nosso dataset é a água contida na caixa d’água, nosso source é a ligação com a companhia de água e, finalmente, os sinks são as torneiras e chuveiros.
Levando agora para um exemplo real, podemos ter um sistema de streaming codificado em um framework/engine de processamento distribuído que poderia ser Apache Flink, Apache Storm, Apache Flume, Apache Samza, dentre outros, que recebe mensagens por meio da leitura de um sistema de mensageria (source) como Apache Kafka, por exemplo, processa-as em tempo real filtrando apenas aquelas que contiverem determinadas palavras-chave e envia uma saída para o Elasticsearch (sink 1) e outras para um banco de dados relacional PostgreSQL (sink 2).
O eixo temporal
Agora que já sabemos o que é um streaming de dados, vamos ao outro eixo: o temporal.
Entendemos o tempo como algo contínuo e que nunca para. Não se assustem! Aqui não iremos tratar questões físicas, como a teoria da relatividade. Nós, enquanto devs, tratamos o tempo como contínuo.
Para uma aplicação que processa streaming, cada dado que entra na nossa engine possui três abstrações de tempo: event time, ingestion time e processing time. O event time representa a hora em que cada evento individual é gerado na fonte de produção, ingestion time o tempo em que os eventos atingem o aplicativo de processamento streaming eprocessing time o tempo gasto pela máquina para executar uma operação específica no aplicativo de processamento de streaming.
Event time, ingestion time e processing time
Afinal de contas, a minha aplicação de streaming processa dados em tempo real? Aí vem a resposta que ninguém gosta de ouvir: “depende do contexto”, ou se preferir, “isso é relativo”. Vamos ao exemplo anterior da leitura de mensagens do Kafka e escrita no Elasticsearch e PostgreSQL, detalhando os tempos do processamento:
Event time
2020-01-01 01:45:55.127
Ingestion time
2020-01-01 01:45:57.122
Processing time
2020-01-01 01:45:57.912
O Ingestion time é responsável por qualquer atraso no processamento do dado e sua possível flutuação assim que o processamento “consome” a mensagem.
Quanto maior a diferença entre o tempo de geração da mensagem (event time) e o tempo que a mensagem chega a engine de streaming (ingestion time), menos “tempo real” será seu processamento. Por isso costumamos, falar em artigos científicos, em tempo “quase-real”. A diferença entre a hora da geração e a que a mensagem é processada é de 2 segundos e 784 milissegundos. Isso representa o “atraso” de apenas uma mensagem. Agora imaginem um throughput de 100 mil mensagens por segundo! Essa diferença de tempo tende a aumentar se o sistema não conseguir consumir e processar essa quantidade de mensagens à medida que chegam.
Mais uma dica de Big Data e streaming: não menospreze os milissegundos. Em grandes volumes, eles fazem muita diferença.
A ordenação dos dados
Outra questão que precisamos estar preparados é o problema que ocorre quando recebemos os dados de mais de uma fonte (source) ou a fonte de dados está com os event times fora de ordem. Se tivermos uma aplicação onde a ordem desses eventos importe, é necessário que haja uma heurística que trate dessa ordenação ou mesmo deste descarte dos dados fora de ordem. A maioria dos frameworks de streaming implementam alguma dessas heurísticas.
Um dos frameworks mais utilizados pelos devs, o Apache Flink possui o conceito de watermarks (marcas d’água). A ideia central é: quando um dado é “carimbado” com uma watermarks, a engine supõe que nenhum dado com tempo inferior (passado) irá chegar.
Como não podemos ter essa certeza, o framework espera que o desenvolvedor escolha como quer tratar esses casos: não toleramos dados com watermarks inferior à última reconhecida (atrasado) ou o framework espera um determinado tempo (10 segundos, por exemplo), ordena as mensagens e envia para processamento. O que chegar fora dessa janela de tempo será descartado. Há a possibilidade ainda de tratar esses dados que seriam descartados, mas fica fora do escopo deste post.
O case Alibaba
Um exemplo real da utilização de streaming de dados em tempo real em um ambiente de Big Data é o case do gigante chinês Alibaba, um grupo de empresas que possui negócios e aplicações focadas em e-commerce, incluindo pagamentos on-line, business-to-business, motor de busca e serviços de computação em nuvem.
Seus dois produtos mais conhecidos são o site de e-commerce (Alibaba.com) e os serviços em nuvem (Alibaba Cloud). O grupo lançou oficialmente em 2016 uma plataforma utilizada para busca e recomendação utilizando Apache Flink. Os mecanismos de recomendação filtram os dados dentro da plataforma de streaming utilizando algoritmos e dados históricos para recomendar os itens mais relevantes ao usuário.
Passos fundamentais para o trabalho com streaming de dados
Neste ponto, já entendemos o que é um streaming de dados e o quão tempo-real ele pode ser. Para finalizarmos, deixaremos algumas dicas para quem quer enveredar por essa área tão onipresente no mercado dev:
Entenda os conceitos de streaming de dados antes de escolher um framework e começar a codar (de novo a dica do livro: Streaming Systems). Isso envolve o conceito de sources, sinks, pipeline, agregações de tempo;
Esteja preparado para grande volumes de dados e altos throughput: isso pode parar sua aplicação por falta de recursos como espaço, memória e processamento;
Pense distribuído! A maioria dos frameworks de streaming possuem o conceito de cluster. Dessa forma, sua aplicação conseguirá escalar horizontalmente e estar preparada para grandes volumes;
Escove os bits. Essa é uma expressão bem dev. Entenda bem a linguagem e o framework que você está utilizando. Tire o máximo deles. Uma estrutura de dados inadequada ou ineficiente para o caso, um laço desnecessário, uma serialização/deserialização onde não é preciso podem minar o desempenho da sua aplicação.
Por último e não menos importante: teste de carga! Faça testes levando sua aplicação ao extremo para identificar possíveis gargalos. Isso não substitui os testes unitários e afins. A finalidade é outra: ver o quanto sua aplicação consegue processar de dados.
É isso aí, pessoal. Espero que tenha suscitado uma vontade de aprender mais sobre streaming de dados em tempo real e suas aplicações.
O 1º Hackathon promovido pelo Tribunal de Contas do Estado do Ceará aconteceu no SebraeLab, entre 24 e 26 de janeiro. O evento reuniu 33 profissionais e estudantes de diversas áreas ligadas à análise de dados, agrupados em oito equipes.
Como publicado pelo próprio TCE-CE, o desafio norteador do Hackathon foi o de “desenvolver uma solução para ler dados abertos dos diversos municípios e do governo do estado do Ceará, encontrar indícios e publicar informações, permitindo a checagem pelos cidadãos”.
Conheça as equipes, e seus temas, com melhor colocação na maratona:
Baião de dados
Centralizar dados dos portais de transparência municipais (macashare.org)
Digimon
Busca de indícios de fraudes e irregularidades em licitações municipais
A ordem de classificação de cada uma das três equipes finalistas será divulgada nesta quinta-feira (30) durante cerimônia na sede do TCE-CE. A premiação seguirá a seguinte ordem: R$ 15.000,00 para o primeiro lugar, R$ 10.000,00 para o 2º e R$ 5.000,00 para o 3º colocado.
Em muitos momentos de nossa carreira, e muito mais no início, o que mais queremos é poder conversar com profissionais presentes há mais tempo no mercado e conhecer suas experiências na área. O cientista de dados do Insight Lab, Valmiro Ribeiro, mestre em Sistemas e Computação, Inteligência Artificial e Processamento de Imagens pela UFRN, selecionou oito dicas fundamentais para quem quer se especializar na área de Ciência de Dados.
A partir daqui, a conversa é com Valmiro Ribeiro:
Uma pergunta bastante comum feita para um cientista de dados é: Como posso me tornar um cientista de dados?
Uma resposta adequada para essa pergunta deve levar em consideração vários fatores, como a área de atuação, afinidade com matemática, afinidade com modelagem de problemas, etc. Contudo, apesar de não existir uma resposta definitiva, aqui vão algumas dicas que julgo essenciais tanto para quem está começando na área quanto para aqueles que já possuem experiência.
1 – Domine a base de conhecimentos da área
É comum na área de ciência de dados que os profissionais possuam backgrounds em diferentes áreas, mas independente de qual área eles tenham vindo, todos devem dominar os conhecimentos básicos da área. Conhecimentos de Programação, Algoritmos e Estruturas de Dados, Aprendizado de Máquinas, Estatística, Probabilidade, Álgebra Linear, Raciocínio Lógico e Banco de Dados são indispensáveis.
2 – Crie um portfólio
A maneira mais fácil de provar para o mundo seus conhecimentos em Data Science é ter um bom portfólio, pois através dele você poderá demonstrar seu conhecimento prático na área. O Github é frequentemente utilizado por cientistas de dados como portfólio, onde são publicados projetos acadêmicos e pessoais, resoluções de desafios conhecidos e soluções resultantes de competições de Data Science, como Hackathons e as competições do Kaggle. Existem outras práticas comuns, mas o principal ponto sempre deve ser mostrar seus conhecimentos para o mundo.
3 – Saiba quais são seus pontos fortes, e principalmente os fracos
Como dito antes, é comum na área de Data Science que as pessoas possuam backgrounds diferentes, e isso faz com que os pontos fortes e pontos fracos de cada um sejam diferentes entre si. Um estatístico pode não ter conhecimentos vastos sobre Banco de Dados, assim como um biotecnologista pode não ser tão bom com Estatística. Dito isso, conhecer suas qualidades e defeitos como cientista de dados é primordial, pois assim você poderá trabalhar em suprimir essas fraquezas e também saberá como pode contribuir melhor nos projetos que você se envolve.
4 – Estude o domínio dos problemas
Um cientista de dados é responsável, entre outras coisas, por extrair informações, validar, descartar e criar hipóteses a respeito dos dados, e isso não é possível sem conhecer o domínio do problema que está sendo abordado. Conhecer o problema permite interpretar dados e resultados de maneira mais eficiente, melhorando todos os processos do ciclo de vida de um projeto de Data Science.
5 – Saiba se comunicar
Cientistas de Dados precisam ser bons contadores de história. Habilidades de comunicação são indispensáveis para quem deseja ingressar nessa carreira, afinal, você precisa traduzir suas descobertas para comunicá-las de forma clara para os outros envolvidos nos projetos. Aqui as competências técnicas e interpessoais andam de mãos dadas. Você deve saber utilizar ferramentas de visualização de dados de maneira efetiva, criando gráficos e tabelas que possam comunicar as suas ideias, ao mesmo tempo que você precisa saber apresentar suas ideias, problemas e resultados para pessoas diferentes.
6 – Participe de competições
Todos os pontos mencionados anteriormente se encontram aqui, pois provavelmente é participando de competições de Data Science que você terá suas primeiras experiências resolvendo problemas reais. Competições, como as do Kaggle e dos hackathons, permitem que você aplique e expanda seus conhecimentos além da teoria, incrementam seu portfólio, permitem que você estude problemas em contextos reais e requerem que você comunique seus resultados de forma clara com uma comunidade, além de permitir que você aprenda novas técnicas/ferramentas e realize uma autoavaliação no fim do processo.
7 – Faça Networking
Conhecer outras pessoas da área (ou de áreas correlacionadas) é fundamental porque te ajuda a conhecer novas ferramentas e pegar dicas com pessoas com experiências diferentes, além de ser uma boa forma de divulgar seu portfólio e compartilhar seus conhecimentos. Lembre-se que um cientista de dados dificilmente trabalhará sozinho, por isso, é importante participar de grupos de estudo, de meet-ups e de comunidades de Data Science para fazer networking.
8 – Continue aprendendo e tentando
Talvez a parte mais difícil de ingressar na área seja manter-se constantemente aprendendo e tentando coisas novas diante dos desafios. Para isso, é preciso ser resiliente e não desistir com o surgimento de novos obstáculos. Você vai começar sem entender muitas coisas, participará de competições sem obter resultados que você julgue satisfatórios, vai reprovar em seleções de emprego, mas tudo isso faz parte da jornada. O importante nessa etapa é usar essas experiências para organizar-se e cobrir seus pontos fracos e melhorar seus pontos fortes.
Creio que essas dicas tenham deixado claro que o caminho para se tornar um cientista de dados não envolve apenas competências técnicas, mas também várias habilidades interpessoais, as quais podem ser subestimadas inicialmente. Finalmente, se você tem interesse de ingressar na área e/ou aprofundar seus conhecimentos, continue acompanhando nossas matérias! Bons estudos!
Ciência de Dados é uma das áreas do conhecimento que mais cresce atualmente, procurando agregar valor à grande quantidade de dados gerada por diversos tipos de dispositivos computacionais existentes.
Cada vez mais o mundo empresarial tenta gerar valor aos seus negócios utilizando técnicas de Data Science. Logo, profissionais habilitados a desenvolver projetos de Ciência de Dados que consigam dar uma vantagem competitiva às empresas estão sendo bastante valorizados.
A preparação dos profissionais para um mercado que precisa cada vez mais deles se fortaleceu no ambiente online. Diversas plataformas virtuais surgiram oferecendo cursos e outros recursos para a especialização, aperfeiçoamento e atualização de quem é ou busca ser um cientista de dados. O número de opções é extenso, isso significa que vamos encontrar conteúdos de grande qualidade, mas não todos.
Para te direcionar aos bons materiais da internet, a seguir, listamos algumas das melhores plataformas para o estudo de Ciência de Dados.
A Data Science Academy é um plataforma brasileira voltada para o ensino de Ciência de Dados, Big Data e outras áreas do conhecimento relacionadas. Eles dispõem de uma vasta gama de cursos online, tanto gratuitos quanto pagos.
Com relação à Ciência de Dados, a plataforma oferece um excelente curso gratuito chamado “Python Fundamentos para Análise de Dados“, com uma carga-horária total de 54 horas. Nesse curso você construirá, inicialmente, uma base sólida da linguagem Python. Assuntos como estruturas de dados, básicas, laços, Programação Orientada a Objetos, tratamento de arquivos e manipulação de banco de dados serão abordados. Em seguida, ferramentas da linguagem voltada para análise de dados são apresentadas, como o pacote Numpy e a biblioteca Pandas. A parte dedicada à Data Science mostra como realizar a análise exploratória dos dados e como conduzir um projeto de Ciência de Dados na prática. Além disso, o curso aborda conceitos de Machine Learning com Python, Deep Learning e a biblioteca TensorFlow . Como bônus no final do curso, uma introdução ao desenvolvimento web com Python é apresentada.
Com uma comunidade composta por mais de três milhões de usuários, o Kaggle é uma plataforma na qual os participantes aprendem muito ao participar das competições promovidas no site.
Companhias do mundo todo disponibilizam seus dados no canal para que analistas tentem desenvolver os melhores modelos para esses dados. Isso gera um excelente acervo de datasets gratuitos dentro da plataforma. Além disso, as soluções desenvolvidas nas competições são compartilhadas dentro dos fóruns de discussão, ou seja, mesmo os usuários que não participaram da competição poderão analisar e aprender com todo esse material produzido por praticantes de data science de todas as partes do mundo, acessando diferentes métodos de abordagem para o mesmo problema.
A Udemy conta com uma grande quantidade de cursos sobre Ciência de Dados.Um dos grandes destaques é o curso dos professores Fernando Amaral e Jones Granatyr chamado “Formação Cientista de Dados com Python e R“.
O curso aborda Fundamentos de Estatística para Ciência de Dados, Séries Temporais, Aprendizado de Máquina, Redes Neurais, Mineração de Textos e etc. Além das videoaulas, o curso também conta com diversos testes de fixação, provas práticas e questões diversas para você conferir se realmente solidificou seus conhecimentos.
Se a língua inglesa não é problema pra você, o curso “Machine Learning A-Z™: Hands-On Python & R In Data Science” é um dos grandes sucessos da plataforma. Com mais de meio milhão de estudantes inscritos, o curso explora a fundo conceitos de Aprendizado de Máquina como regressões, classificadores, técnicas de agrupamento (clusterização), regras de associação, aprendizado profundo (deep learning) e muito mais.
Outras formas de aprendizado
Se você não gosta de vídeo-aulas e prefere procurar conhecimento de forma mais independente, o site Analytics Vidhya criou um infográfico que mostra o caminho das pedras os assuntos mais importantes para quem quiser se tornar um Cientista de Dados em 2020.
Bons estudos!
Se quiser continuar aprendendo sobre Data Science e Programação, siga acompanhando nossas matérias.
Não pare por aqui, leia “12 bibliotecas do Python para análise de dados espaço-temporais” (parte 1) e (parte 2)
A Universidade Federal do Ceará tem se destacado no Projeto SINESP Big Data e Inteligência Artificial, desenvolvido pela UFC em parceria com a Secretaria da Segurança Pública e Defesa Social do Ceará (SSPDS). Na última sexta-feira (20), o reitor da UFC, Prof. Cândido Albuquerque, recebeu ofício do Ministério da Justiça e Segurança Pública (MJSP) destacando os “excelentes resultados” dos trabalhos desenvolvidos pela Universidade no âmbito do projeto, vinculado ao Sistema Nacional de Informações de Segurança Pública (SINESP).
O documento, assinado pelo delegado federal Wellington Clay Porcino Silva, diretor de Gestão e Integração de Informações da Secretaria Nacional de Segurança Pública (SENASP), aponta como resultado positivo “a inovação científica dos produtos [desenvolvidos pela UFC], que apresentam recursos não presentes em nenhuma solução de mercado“.
A qualidade dos produtos e serviços, o nível de gestão e comprometimento da equipe, a antecipação das entregas de produtos e serviços, e a implantação das ferramentas do projeto nos estados participantes também são apresentados pelo delegado federal como aspectos que fundamentam a afirmação de que os trabalhos realizados pela Universidade “têm obtido excelentes resultados”.
Para o reitor Cândido Albuquerque, a mensagem do MJSP ressalta a importância de se criar na UFC uma unidade para integrar todas as ações desenvolvidas na área de inteligência artificial. “As instituições estão buscando a inteligência artificial como mecanismo de solução de seus problemas. E nós precisamos ter uma unidade que integre todas as ações de nossos diversos cursos na área de inteligência artificial. Já temos bons trabalhos, mas precisamos fortalecer nossa ação nesse campo”, considera.
Coordenado pelo Prof. José Macêdo, do Departamento de Computação da UFC, o Projeto SINESP Big Data e Inteligência Artificial desenvolveu ferramentas que possuem, entre outras funcionalidades, análise de manchas criminais, visualização de posicionamento de viaturas em tempo real, acionamento de câmeras, identificação de impressão digital e gestão de policiamentos.
O produto já está em funcionamento nos estados participantes do Programa Nacional de Enfrentamento à Criminalidade Violenta (Em Frente, Brasil), projeto-piloto implementado no fim de agosto pelo Ministério da Justiça e Segurança Pública com o objetivo de reduzir o número de crimes violentos no país por meio de articulação entre a União, os estados e os municípios.
De acordo com o Ministério da Justiça e Segurança Pública, nos últimos três meses, o número de homicídios caiu 44,7% nas cincos cidades participantes do programa: Ananindeua (Pará), Cariacica (Espírito Santo), Goiânia (Goiás), Paulista (Pernambuco) e São José dos Pinhais (Paraná).
Fonte: Coordenadoria de Comunicação Social e Marketing Institucional – fone: (85) 3366 7331
É uma biblioteca do Python voltada para análise de redes urbanas. Seus recursos principais incluem: o download automatizado de fronteiras políticas e a construção de pegadas, o download personalizado e automatizado, a construção de dados de rede de rua do OpenStreetMap, a correção algorítmica da topologia de rede, a capacidade de salvar redes de rua em disco como shapefiles, arquivos GraphML ou SVG, e a capacidade de analisar redes de rua, incluindo rotas de cálculo, projetando e visualizando redes, além de calcular medidas métricas e topológicas.
Se você quer saber mais sobre OSMnx, nós indicamos este artigo:
É uma biblioteca código aberto do Python voltada para visualização de dados geoespaciais, em mapas interativos, utilizando a biblioteca Leaflet.js. O Folium possibilita uma fácil utilização dos elementos gráficos do Leaflet, permitindo uma grande flexibilidade para manipular os atributos de um mapa e de seus elementos. Além disso, ele possui diversas visualizações implementadas, tendo destaque para a facilidade de uso das visualizações em função do tempo, como o HeatMapWithTime. O Folium é uma ótima biblioteca quando deseja-se montar uma visualização final dos dados com uma maior riqueza de detalhes interativos.
É uma biblioteca Python que converte um gráfico matplotlib em uma página da web contendo um mapa Leaflet. O objetivo do Mplleaflet é permitir o uso de Python e Matplotlib para visualizar dados geográficos em mapas deslizantes sem ter que escrever qualquer Javascript ou HTML. Além disso, ele automatiza a escolha do mapa base, o usuário não precisa se preocupar com o seu conteúdo, ou seja, estradas, linhas costeiras, etc.
É uma biblioteca Python para visualização de dados perdidos em datasets. Suas visualizações incluem diversos gráficos (matriz, barras, mapa de calor, dendrograma, dentre outros) para analisar lacuna de dados ausentes em séries temporais.
É uma coleção de algoritmos matemáticos e funções de conveniência construída sobre a extensão NumPy de Python e, portanto, com alto desempenho. SciPy fornece recursos para acessar classes de alto nível para manipulação e visualização de dados. Com o SciPy, uma sessão Python interativa torna-se um ambiente de processamento de dados e protótipos de sistemas concorrentes, como MATLAB, IDL, Octave, R-Lab e SciLab.
Ela é uma biblioteca que foca em ler e escrever dados, em estilo Python IO padrão. Fiona pode ler e escrever dados usando formatos GIS multicamadas e sistemas de arquivos virtuais compactados. Em trabalhos de análise de trajetória, Fiona é uma ótima ferramenta, visto que ela é fácil de usar, flexível e confiável.
A Segurança Pública está intrinsecamente ligada à cultura e ao cotidiano social. E o crime se vale de comportamentos e janelas de oportunidades para ser consumado. Diante disso, o crescimento desordenado das cidades, o aumento dos aglomerados subnormais e das áreas de patrulhamento impuseram novos desafios à administração pública. Tornou-se economicamente inviável manter um efetivo capaz de “saturar” todas as áreas críticas.
Hoje é economicamente inviável manter efetivos para monitorar todas as áreas; no Ceará, foram agregadas mais tecnologia e inteligência de cenários às atividades rotineiras.
Os modelos de policiamento unicamente estatísticos, os famosos “hotspots”, começaram a ruir quando a criminalidade, devido à popularização do uso do veículo automotor, passou a utilizar o vetor mobilidade e manobrabilidade em suas práticas delitivas, causando um reativismo difuso do policiamento.
A identificação dessa mudança no comportamento delitivo e a necessidade de adequação do policiamento a esse novo padrão, integram o conceito de Mobilidade do Crime, serão apresentadas aqui de maneira resumida.
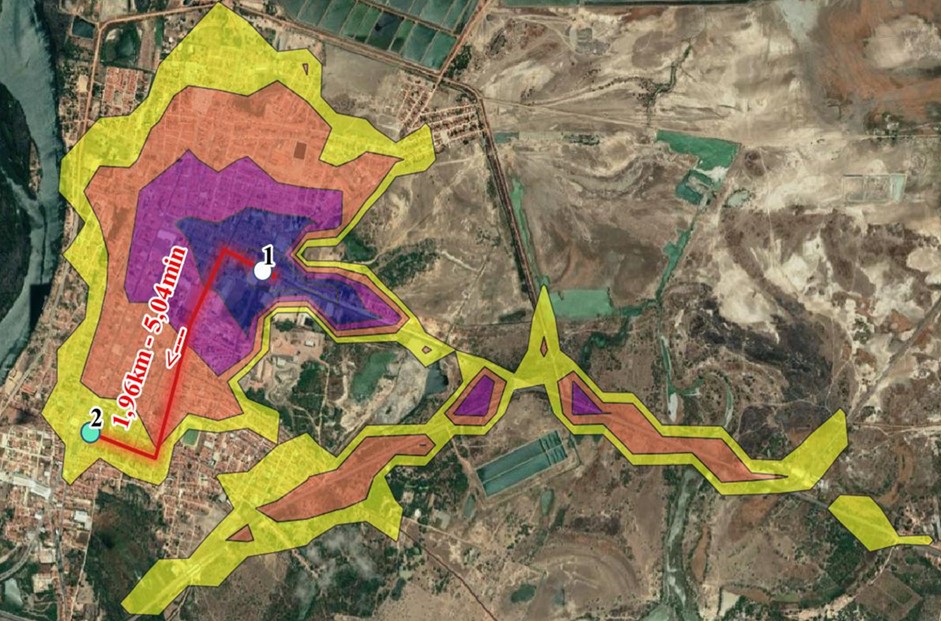
Para evidenciar o conceito e demonstrar a necessidade de se criar um novo modelo de policiamento, apresentamos abaixo o mapa isócrono (Figura 1) de uma conduta delitiva. A imagem demonstra que a execução do crime está mais associada à motivação do agressor e às condições de vulnerabilidade da vítima do que a “hotspots”.
A Figura 1 apresenta dois pontos, que correspondem a sensores integrados ao SPIA (Sistema Policial Indicativo de Abordagem). O veículo monitorado foi utilizado no cometimento de um delito entre os pontos 1 e 2, levando aproximadamente 5 minutos para se deslocar entre as duas localidades.
Considerando a manobrabilidade que esses infratores teriam num intervalo de 5 minutos após passar pelo ponto 1, o delito poderia ter sido cometido em qualquer posição da área demarcada pela cor amarela no mapa. Dito de outro modo, partindo do ponto 1 e levando em consideração os 5 minutos utilizados para o cometimento do delito e a fuga, esses infratores poderiam atuar em uma área correspondente a 7,66 km².
(1) Mapa isócrono de uma conduta delitiva real ocorrida em 2018 em Aracati/CE. Fonte: SUPESP-CE
É impossível, com tamanha área de manobrabilidade, imaginar que uma viatura posicionada em determinado ponto da cidade seria capaz de prevenir o cometimento de um crime pretendido por um infrator motivado, uma vez que este aguardaria o momento oportuno, em que houvesse a vulnerabilidade da vítima e a ausência de policiamento para o cometimento da infração. Não estamos, com isso, querendo dizer que a presença policial não previne o cometimento de infrações, mas demonstrar que essa prevenção é bastante limitada.
Para fazer frente a esse desafio, o Estado do Ceará começou a repensar sua estratégia de Segurança Pública e a agregar mais tecnologia e inteligência de cenários às atividades rotineiras, cujo primeiro projeto foi a Política de Combate à Mobilidade do Crime.
O combate à Mobilidade do Crime, resultado da integração entre a Secretaria de Segurança Pública do Estado do Ceará e a Polícia Rodoviária Federal do Ceará, apoia-se em 3 pilares:
O Sistema Policial de Indicativo de Abordagem (SPIA), uma inteligência artificial que integra diversos sensores espalhados pela cidade e tem a capacidade de localizar veículos envolvidos em delitos, em tempo real;
A montagem de cercos inteligentes pelos operadores da Coordenadoria Integrada de Operações de Segurança (CIOPS) que, ao receberem a localização de veículos suspeitos pelo SPIA, orientam as viaturas para o trabalho de cerco e captura através do sistema de videomonitoramento;
E o aumento do efetivo policial para motopoliciamento, o que permite uma maior mobilidade da Polícia Militar nas ocorrências, culminando com a redução no tempo de resposta às ocorrências.
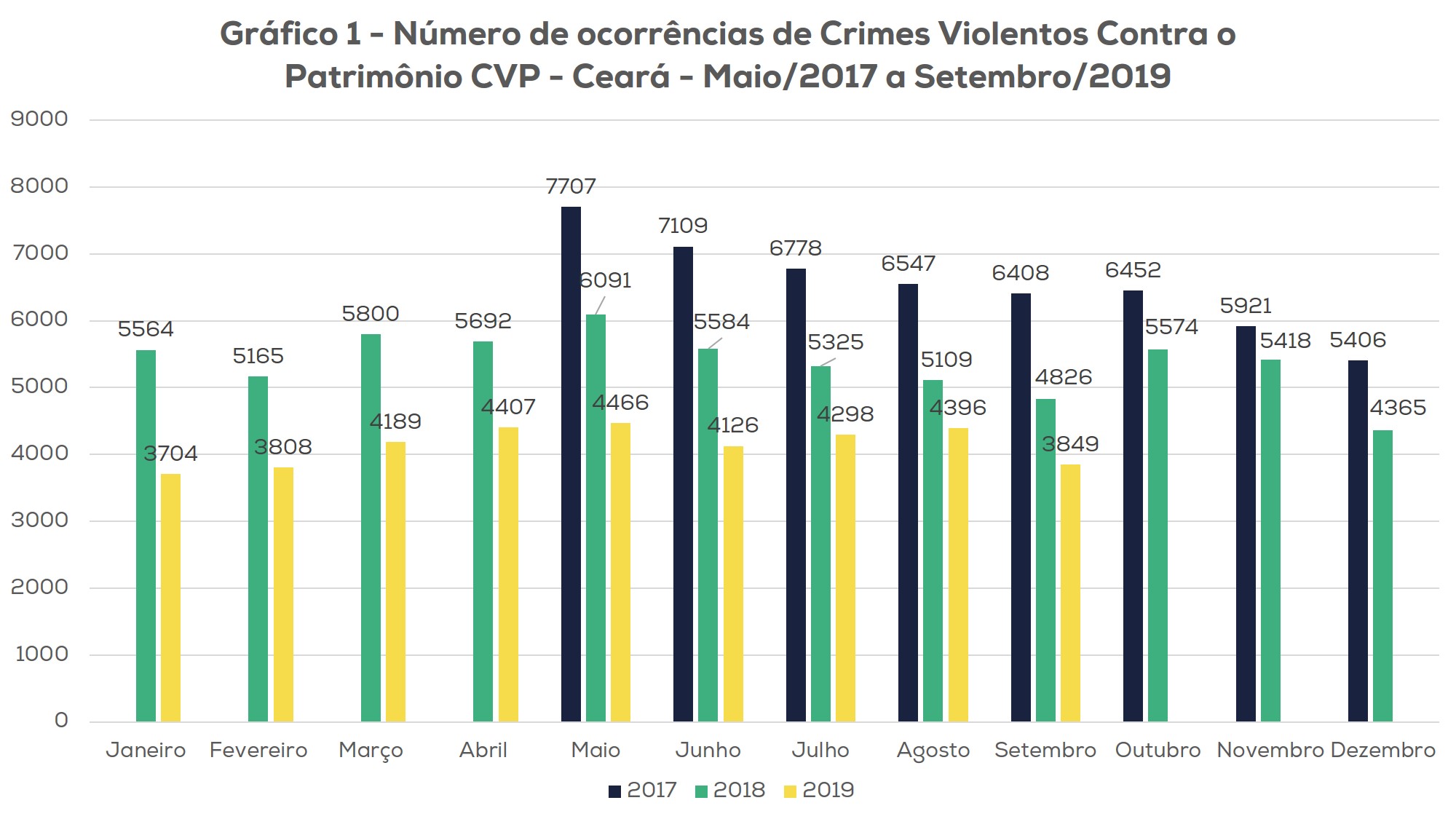
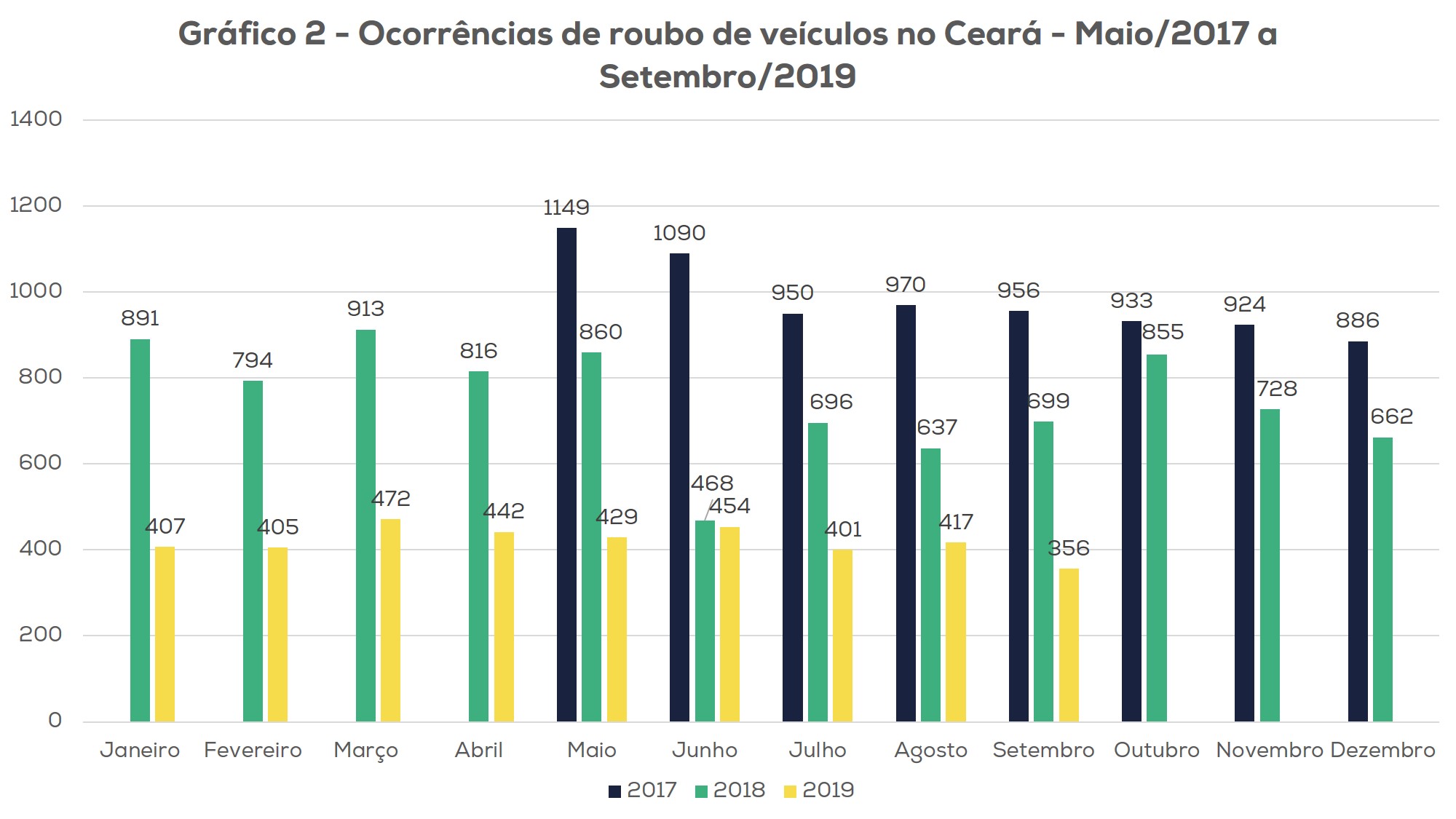
Dessa simbiose entre homem e tecnologia, que possui similaridades com a indústria 4.0, o Estado do Ceará vem colhendo os frutos de 28 meses de redução nos roubos de veículos e roubos de maneira geral, como pode ser verificado nos Gráficos 1 e 2. A redução dos roubos de maneira geral se deu principalmente porque, como exemplificamos acima, o veículo serve como meio logístico para o cometimento da maioria dos delitos.
Fica evidente, portanto, que, ao “quebrar” a “mobilidade do criminoso”, o seu raio de atuação se torna cada vez mais limitado, mais próximo do local onde reside ou se homizia, facilitando o planejamento e a concentração do policiamento em locais estratégicos.
Gráfico 1 – Evolução do CVP no Ceará entre 2017 e 2019 após o início da Política de Combate a Mobilidade do Crime. Fonte: GEESP/SUPESP-CE
Gráfico 2 – Evolução dos crimes de roubo de veículos no Ceará entre 2017 e 2019 após o início da Política de Combate a Mobilidade do Crime. Fonte: GEESP/SUPESP-CE
Em linhas gerais buscamos mostrar, a partir das informações apresentadas, como o uso da ciência policial e da tecnologia podem fazer uma grande diferença no planejamento de uma Estratégia de Segurança Pública moderna. O impacto começa a surgir com força. Em um exercício preliminar, utilizando parâmetros de custos da violência da Confederação Nacional das Indústrias (CNI), estimamos uma redução em cerca de 1,3 bi de gastos diretos devido a redução dos roubos de veículos, custos dos seguros e homicídios.
* Aloísio Lira é Superintendente de Pesquisa e Estratégia de Segurança Pública do Ceará, Agente Especial de Polícia Rodoviária Federal e vice-presidente do Conselho Estadual de Segurança Pública do Ceará
Dados espaço-temporais envolvem a união de duas áreas: séries temporais e Geoestatística. Com esses dados você observa o evento por duas frentes: do ponto de vista temporal e a partir do local em que isso acontece.
Uma linha de pesquisa desenvolvida aqui no Insight Lab é a análise de dados espaço-temporais. Nossos pesquisadores, Nicksson Arrais, Francisco Carlos Júnior e João Castelo Branco, prepararam uma seleção com opções de bibliotecas para trabalhar com dados espaço-temporais no ambiente Python.
É um projeto open source para facilitar o trabalho com dados geoespaciais em Python. GeoPandas estende os tipos de dados do pandas fornecendo operações espaciais em tipos geométricos. O GeoPandas combina as capacidades do Pandas e da biblioteca Shapely, fornecendo operações geoespaciais do Pandas e uma interface de alto nível para múltiplas geometrias do Shapely. Ele permite que você faça facilmente operações em Python que de outra forma exigiria um banco de dados espacial como o PostGIS.
É uma biblioteca multiplataforma de código aberto para ciência de dados geoespaciais, com ênfase em dados vetoriais geoespaciais escritos em Python. PySAL suporta o desenvolvimento de aplicações de alto nível para análise espacial, como a detecção de clusters espaciais e hot-spots, construção de outliers de gráficos de regressão de dados espaciais e modelagem estatística em redes geograficamente incorporados econometria espacial exploratória e análise de dados espaço-temporais. Os analistas espaciais que possam estar a realizar projetos de investigação que exijam um scripting personalizado, uma análise de simulação extensiva, ou aqueles que procuram fazer avançar o estado da arte na análise espacial devem também considerar o PySAL como uma base útil para o seu trabalho.
É uma biblioteca de código aberto para análises de trajetória, desenvolvida pelo Insight Lab, que envolve tanto as visualizações de trajetórias, pontos de interesses e eventos, quanto o processamento de dados sobre múltiplas trajetórias de forma eficiente. O PyMove fornece ao usuário um ambiente único de análise e visualizações de dados de trajetória, sendo bastante fácil de usar, extensível e ágil.
É uma biblioteca para simulação e análise da mobilidade humana em Python. A biblioteca permite: gerir e manipular dados de mobilidade de vários formatos (registos de detalhes de chamadas, dados GPS, dados de redes sociais baseadas na localização, dados de inquéritos, etc.); extrair métricas e padrões de mobilidade humana de dados, tanto a nível individual como colectivo (por exemplo, comprimento dos deslocamentos, distância característica, matriz origem-destino, etc.). O Scikit-Mobility conta com diversos modelos para simular trajetórias e métricas para comparação de trajetórias como raio de rotação, motivos diários, entropia de mobilidade, matrizes origem-destino, além de uma implementação simples e eficiente baseada nas bibliotecas populares como Python NumPy, Pandas e Geopandas
Confira também este artigo sobre o Scikit-Mobility:
É uma extensão da biblioteca Pandas e sua extensão espacial GeoPandas para adicionar funcionalidade quando se lida com dados de trajetória. No Moving Pandas, uma trajetória é uma série de geometrias ordenadas pelo tempo. Essas geometrias e atributos associados são armazenados em um GeoDataFrame, uma estrutura de dados fornecida pela biblioteca de GeoPandas. A principal vantagem do Moving Pandas é que, sendo baseado no GeoPandas, ele permite que o usuário execute várias operações em trajetórias, como recortá-las com polígonos e computar interseções com polígonos. No entanto, por estar focado no conceito de trajetória, o Moving Pandas não implementa nenhuma característica específica da análise de mobilidade, como leis estatísticas de mobilidade, modelos generativos, funções padrão de pré-processamento e métodos para avaliar o risco de privacidade em dados de mobilidade.
Uma das principais bibliotecas em Python para manipulação e análise de objetos geométricos planares. Devido à sua construção ser baseada na biblioteca GEOS (mesma engine do PostGIS), a biblioteca Shapely possui as principais funções para operações de objetos geométricos. A partir das estruturas de dados principais de ponto, linha e polígonos você conseguirá visualizar objetos geométricas e realizar facilmente operações simples como: interseção e união. E também operações mais complexas como convex hull e construção de estrutura com múltiplos objetos geométricos. Para trabalhar com dados georreferenciados em Python, a nossa dica é que Shapely seja umas das primeiras bibliotecas estudadas.
Continue acompanhando nossas publicações. Em breve postaremos a segunda parte desta lista com mais 6 bibliotecas. Até logo!
Nós usamos cookies para melhorar sua experiência de navegação. Ao navegar no site, você concorda com a política de monitoramento de cookies. Se você concorda, clique em OK. Para ter mais informações sobre como isso é feito, acesse nosso Aviso de Privacidade.OKAviso de Privacidade