A nova edição do nosso webinar já está programada. Agora, o tema debatido será “Por onde começar e o que você deve saber antes de iniciar sua carreira em Ciência de Dados”.
Nesta conversa, cinco profissionais compartilharão suas experiências no mercado de Data Science sobre a perspectiva da evolução da Ciência de Dados e a caracterização atual do mercado, destacando as pesquisas em alta, o perfil do profissional almejado na área e também como acontece o fluxo produtivo entre os setores acadêmico e privado.
Durante o webinar, também será apresentado o curso gratuito e online de Ciência de Dados produzido pelo Insight Lab.
Participantes
José Macêdo: Coordenador do Insight Lab, Cientista-chefe de Dados do Governo do CE e professor da UFC
Regis Pires:Coordenador de Capacitação do Insight Lab, cientista de dados do Íris e professor da UFC
Lívia Almada:Pesquisadora no Insight Lab e professora da UFC
Lucas Peres:Desenvolvedor Full Stack no Insight Lab
André Meireles:Pesquisador no Virtus UFCG e professor na UFC
Agenda
Dia: 16 de setembro
Horário: 16h
A transmissão acontecerá no canal do Insight Lab no Youtube,aqui.
Este evento é feito para você, então se sinta à vontade para enviar suas perguntas através do chat no YouTube, elas serão respondidas no último bloco do webinar.
No Telegram, você encontra milhares de canais sobre os temas mais variados, entre eles, o de Ciência de Dados.
Nessa imensidão de conteúdos, é sempre bom ter uma dica para encontrar os melhores. Hoje, nós reunimos uma lista com 11 canais de Ciência de Dados no Telegram que todo cientista de dados precisa participar.
Com uma plataforma online de competições em IA, a bitgrit, seu grupo no telegram é voltado para cientistas de dados compartilharem seus conhecimentos e dúvidas na área.
Canal dedicado à Ciência de Dados, Machine Learning, Deep Learning e Redes Neurais. Aqui você vai encontrar livros, dicas de cursos, exemplos de aplicações e outros materiais.
O canal traz um universo de conteúdos para você aprender Visão Computacional, Machine Learning, Deep Learning, IA e programação em Python.
Esse foi o último item da nossa lista, mas você também deve ter seus canais de Data Science preferidos, compartilha eles aqui nos comentários e ajude essa lista a crescer.
Até onde uma ideia pode chegar? “Até o céu!”, diria Santos-Dumont.
É, Santos, elas podem ir além. Elas vão mais longe, e são muito mais significativas, quando são compartilhadas e se juntam a uma outra ideia.
Falando em ideias se encontrando, a gente já pensa no TED Talks, um evento que começou em 1984 juntando tecnologia, entretenimento e design, com seu slogan “Ideas worth spreading”. O TED é um dos eventos de maior audiência do mundo, e se tornou o fenômeno que conhecemos quando passou a disponibilizar as palestras gratuitamente nos meios online. A partir daí, as palestras puderam ser espalhadas em uma outra escala, chegando a um público de milhões.
O Ted é uma ideia que se espalhou e, com 36 anos de existência, já trouxe ao palco algumas das pessoas mais inspiradoras, criativas e inovadoras do campo da tecnologia. Em meio a esse universo de grandes conversas, hoje, nós vamos compartilhar a nossa lista dos 10 melhores Ted Talks de IA, dados e tecnologia.
A forma como a lista está ordenada não significa uma ordem de preferência. Olha as palestras que nós escolhemos:
A inteligência artificial está ficando mais inteligente rapidamente. Dentro deste século, sugerem pesquisas, uma IA de computador poderá ser tão “inteligente” quanto um ser humano. E então, diz Nick Bostrom, nos ultrapassará: “A inteligência das máquinas é a última invenção que a humanidade precisará fazer”. Filósofo e tecnólogo, Bostrom nos pede que pensemos muito sobre o mundo que estamos construindo agora, impulsionado por máquinas pensantes. Nossas máquinas inteligentes ajudarão a preservar a humanidade e nossos valores ou terão valores próprios?
Você nunca viu dados sendo apresentados assim. Com o drama e a urgência de um apresentador de esportes, o guru das estatísticas Hans Rosling desmascara mitos sobre o chamado “mundo em desenvolvimento”.
O aprendizado de máquina não é apenas para tarefas simples, como avaliar o risco de crédito e classificar e-mails. Hoje, ele é capaz de fazer aplicações muito mais complexas, como classificar dissertações e diagnosticar doenças. Com esses avanços, surge uma pergunta desconfortável: um robô fará o seu trabalho no futuro?
Quando uma criança muito jovem olha para uma foto, ela pode identificar elementos simples: “gato”, “livro”, “cadeira”. Agora, os computadores estão ficando inteligentes o suficiente para fazer isso também. O que vem depois? Em uma palestra arrebatadora, a especialista em visão computacional Fei-Fei Li, codiretora do Stanford’s Human-Centered AI Institute, descreve o estado da arte, incluindo o banco de dados de 15 milhões de fotos que sua equipe construiu para “ensinar” um computador a entender imagens, e as principais ideias que estão por vir.
Conheça a AIVA, uma inteligência artificial que foi treinada na arte da composição musical lendo mais de 30.000 das melhores partituras da história. Em uma palestra e demonstração hipnotizantes, Pierre Barreau toca composições criadas pela AIVA e compartilha seu sonho: criar trilhas sonoras originais ao vivo baseadas em nossos humores e personalidades.
Vivemos em um mundo administrado por algoritmos, programas de computador que tomam decisões ou resolvem problemas para nós. Nesta conversa engraçada e fascinante, Kevin Slavin mostra como os algoritmos modernos determinam os preços das ações, as táticas de espionagem e até os filmes que você assiste. Mas ele pergunta: se dependemos de algoritmos complexos para gerenciar nossas decisões diárias – quando começamos a perder o controle?
Nesta conversa informativa e inspiradora, Sebastian Thrun discute o progresso do aprendizado profundo, por que não devemos temer a IA e como a sociedade será melhor se o trabalho tedioso for feito com a ajuda de máquinas. “Apenas 1% das coisas interessantes já foram inventadas”, diz Thrun. “Eu acredito que todos nós somos insanamente criativos … [IA] nos permitirá transformar a criatividade em ação”.
Neste TEDx, a pesquisadora da MITRE Corporation, Jaya Tripathi, apresenta métodos fundamentais em Ciência de Dados ao descrever seu processo para chegar à verdade em sua pesquisa sobre demografia e dependência.
Os algoritmos de IA tomam decisões importantes sobre você o tempo todo. Mas o que acontece quando essas máquinas são construídas com viés humano codificado em seus sistemas? A tecnóloga Kriti Sharma explora como a falta de diversidade na tecnologia está se infiltrando em nossa IA, e oferece três maneiras pelas quais podemos começar a criar algoritmos mais éticos.
Quão inteligentes nossas máquinas podem nos tornar? Tom Gruber, co-criador da Siri, quer criar uma “IA humanística” que aumente e colabore conosco, em vez de competir (ou substituir). Ele compartilha sua visão sobre um futuro em que a IA nos ajuda a alcançar um desempenho sobre-humano na percepção, criatividade e função cognitiva, desde turbinar nossas habilidades de design até nos ajudar a lembrar tudo o que lemos e o nome de todos que já conhecemos. “Estamos no meio de um renascimento na IA”, diz Gruber. “Toda vez que uma máquina fica mais inteligente, nós ficamos mais inteligentes”.
E você, quais Ted Talks mais te marcaram? Compartilha com a gente nos comentários.
*Os resumos apresentados sobre as palestras foram adaptados do site do TED.
Diante de um cenário tão complexo quanto o atual, onde grande parte da população se sente desorientada e assustada, é fundamental difundir informações corretas e claras. Por isso, estamos lançando o 1º webinar do Insight Lab: “Como os modelos epidemiológicos são aplicados ao Covid-19: entendendo casos reais”.
Com transmissão online e gratuita no YouTube, o evento acontecerá nesta quarta-feira (20 de maio), começando às 16h, e contará com cinco especialistas que esclarecerão, através de casos reais observados na pandemia de 2020, os modelos epidemiológicos usados para entender e prever o comportamento do Covid-19 entre as populações.
Faça parte da conversa!
Serviço
Dia: 20 de maio
Horário: 16h
Clique aqui para acessar o webinar e adicionar um lembrete na agenda.
Olha quem acabou de chegar na internet: nosso “Curso de Introdução ao Docker”. O curso foi ministrado na Universidade Federal do Ceará (UFC), em 2019, e agora está disponível em nosso canal no YouTube.
Gustavo Coutinho: Professor no Instituto Federal de Educação, Ciência e Tecnologia do Ceará (IFCE) e doutorando em Ciências da Computação na Universidade Federal do Ceará (UFC)
Lucas Peres: Desenvolvedor full-stack e doutorando em Ciências da Computação na Universidade Federal do Ceará (UFC)
Regis Pires: Cientista de dados do Insight Lab e do Íris (Lab de Inovação e Dados do Ceará).
O mundo empresarial vive em constante transformação e avanço. Para acompanhar esse ritmo é preciso se atualizar e a inovação é item imprescindível para a continuidade das organizações. Os processos estão cada vez mais velozes e o desafio de manter a rentabilidade força as empresas a encontrarem maneiras de se adaptarem às novas realidades. E aí surge uma questão primordial: como estruturar sua empresa da melhor forma possível?
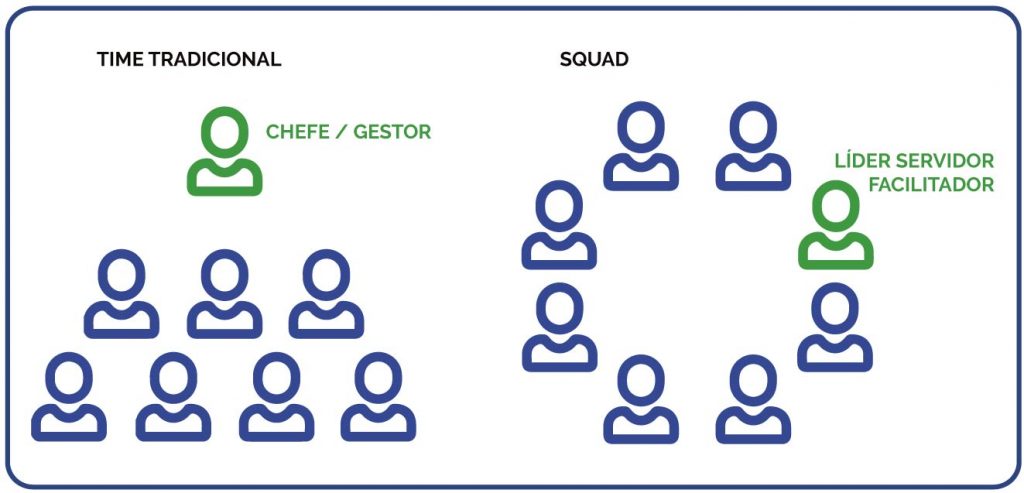
CONCEITO DE SQUAD
O Squad (esquadrão) é um modelo organizacional que estrutura a divisão das equipes empresariais em pequenos times multidisciplinares. Cada uma com a missão de solucionar desafios específicos de produtos. O Squad é composto por membros de diferentes funções, sincronizados e autônomos, em grupos pequenos e liderados por um colaborador individual, o líder.
O Squad (esquadrão) é um modelo organizacional que estrutura a divisão das equipes empresariais em pequenos times multidisciplinares. Cada uma com a missão de solucionar desafios específicos de produtos. O Squad é composto por membros de diferentes funções, sincronizados e autônomos, em grupos pequenos e liderados por um colaborador individual, o líder.
COMO SURGIU O MODELO DE SQUAD
Em 2014, o vídeo intitulado Spotify Engineering Culture ou Cultura de Engenharia do Spotify – serviço de distribuição de música pela internet – deu o pontapé inicial ao que popularmente ficou conhecido como “modelo Spotify Squads”.
Em sua formação inicial, o Spotify era uma pequena organização que utilizava o Scrum – estrutura de trabalho que busca auxiliar times a construírem e desenvolverem seus produtos em ambientes complexos. Com o crescimento da empresa e o aumento da equipe, percebeu-se que o modelo Scrum não se adequava mais tanto à empresa como antes. Então, concluíram que a metodologia Ágil – do Manifesto Ágil para Desenvolvimento de Software, assinado em 2001 em Utah, era mais importante do que um modelo específico. As metodologias ágeis, em geral, defendem o planejamento adaptativo, times auto-organizados e multidisciplinares, melhoria contínua e o desenvolvimento evolucionário.
A partir daí, o Spotify reformulou seu “Scrum Master” para “ Agile Coach”, que funcionaria como um líder-colaborador capaz de incentivar uma melhoria contínua. Depois dessa primeira mudança, as equipes passaram a ser chamadas de Squads.
MODELO SQUAD NO INSIGHT LAB
O Insight Lab implementou a metodologia Squad para dar mais rapidez aos seus trabalhos e uma maior autonomia aos seus membros. Liderado por um coordenador especialista em sua área, cada Squad possui a autonomia necessária para desenvolver um trabalho mais ágil e com ótimos resultados.
Cada esquadrão é coordenado por um líder, que tem o papel de facilitador. Apesar do título, o líder não está em uma posição superior ou inferior ao restante da sua equipe, sendo o seu papel tão importante quanto o de todos os outros membros do esquadrão.
A composição desses Squads, multidisciplinares, vai desde profissionais especializados a estudantes de graduação, passando por pesquisadores nacionais e internacionais. Com um grupo misto, cada membro tem a oportunidade de conhecer mais sobre as outras funções e construir um aprendizado colaborativo.
IMPACTOS DA IMPLEMENTAÇÃO DO MODELO SQUAD
Agilidade e produtividade
Com uma equipe mais enxuta, os squads conseguem agilizar os processos por exigir menos burocracia e menos necessidade de reuniões. No modelo de equipe tradicional existe a necessidade de uma relação entre setores no processo, enquanto no Squad toda a comunicação acontece, unicamente, dentro da equipe. Não há a dificuldade de organizar horários e prazos com um número maior de pessoas.
Motivação pelo sucesso do projeto
Com o nivelamento das responsabilidades, o grupo passa a desenvolver um sentimento de coletividade mais apurado, e a motivação é consequência diante do reconhecimento também mais democrático entre os membros quando o sucesso acontece.
Colaboração além das funções
Nos Squads, uma grande vantagem é a contribuição de todos os membros durante os processos, de diversas maneiras, independente da sua especialização. Isso enriquece ainda mais a construção do produto que recebe visões diferentes de cada pessoa.
A colaboração também acontece na parceria em dividir os trabalhos, ou mais ainda, na ajuda a um colega na realização de uma tarefa para que a execução dos trabalhos não seja comprometida. Dentro de um Squad o sucesso é de todos.
E você, também faz parte de um Squad?
Que modelo organizacional é usado no seu trabalho?
A capacidade de classificar e reconhecer certos tipos de dados vem sendo exigida em diversas aplicações modernas e, principalmente, onde o Big Data é usado para tomar todos os tipos de decisões, como no governo, na economia e na medicina. As tarefas de classificação também permitem que pesquisadores consigam lidar com a grande quantidade de dados as quais têm acesso.
Neste post, iremos explorar o que são essas tarefas de classificação, tendo como foco a classificação multi-label (multirrótulo) e como podemos lidar com esse tipo de dado. Todos os processos envolvidos serão bem detalhados ao longo do texto; na parte final da matéria vamos apresentar uma aplicação para que você possa praticar o conteúdo. Prontos? Vamos à leitura! 😉
Diferentes formas de classificar
Livrarias são em sua maioria lugares amplos, às vezes com um espaço para tomar café, e com muitos, muitos livros. Se você nunca entrou em uma, saiba que é um lugar bastante organizado, onde livros são distribuídos em várias seções, como ficção-científica, fotografia, tecnologia da informação, culinária e literatura. Já pensou em como deve ser complicado classificar todos os livros e colocá-los em suas seções correspondentes?
Não parece tão difícil porque esse tipo de problema de classificação é algo que nós fazemos naturalmente todos os dias. Classificação é simplesmente agrupar as coisas de acordo com características e atributos semelhantes. Dentro do Aprendizado de Máquina, ela não é diferente. Na verdade, a classificação faz parte de uma subárea chamada Aprendizado de Máquina Supervisionado, em que dados são agrupados com base em características predeterminadas.
Basicamente, um problema de classificação requer que os dados sejam classificados em duas ou mais classes. Se o problema possui duas classes, ele é chamado de problema de classificação binário, e se possui mais de duas classes, é chamado de problema de classificação multi-class (multiclasse). Um exemplo de um problema de classificação binário seria você escolher comprar ou não um item da livraria (1 para “livro comprado” e 0 para “livro não comprado”). Já foi citado aqui um típico problema de classificação multi-class: dizer a qual seção pertence determinado livro.
O foco deste post está em um variação da classificação multi-class: a classificação multi-label, em que um dado pode pertencer a várias classes diferentes. Por exemplo, o que fazer com um livro que trata de religião, política e ciências ao mesmo tempo?
Como lidar com dados multi-label
Bem, não sabemos com exatidão como as livrarias resolvem esse problema, mas sabemos que, para qualquer problema de classificação, a entrada é um conjunto de dados rotulado composto por instâncias, cada uma associada a um conjunto de labels (rótulos ou classes).
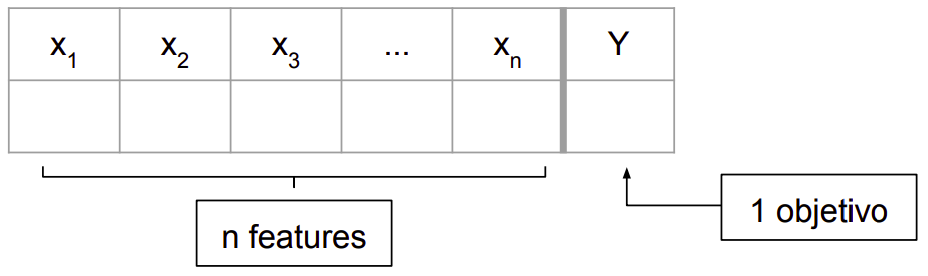
Conjunto de dados para um problema de classificação multi-class
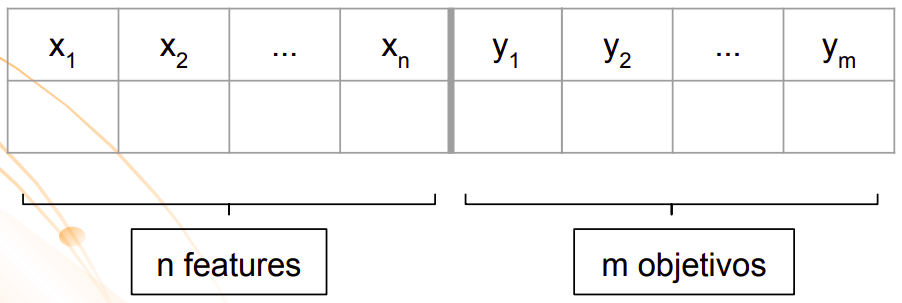
Conjunto de dados para um problema de classificação multi-label
Para que algo seja classificado, um modelo precisa ser construído em cima de um algoritmo de classificação. Tem como garantir que o modelo seja realmente bom antes mesmo de executar ele? Sim! É por isso que os experimentos para esse tipo de problema normalmente envolvem uma primeira etapa: a divisão dos dados em treino (literalmente o que será usado para treinar o modelo) e teste (o que será usado para validar o modelo).
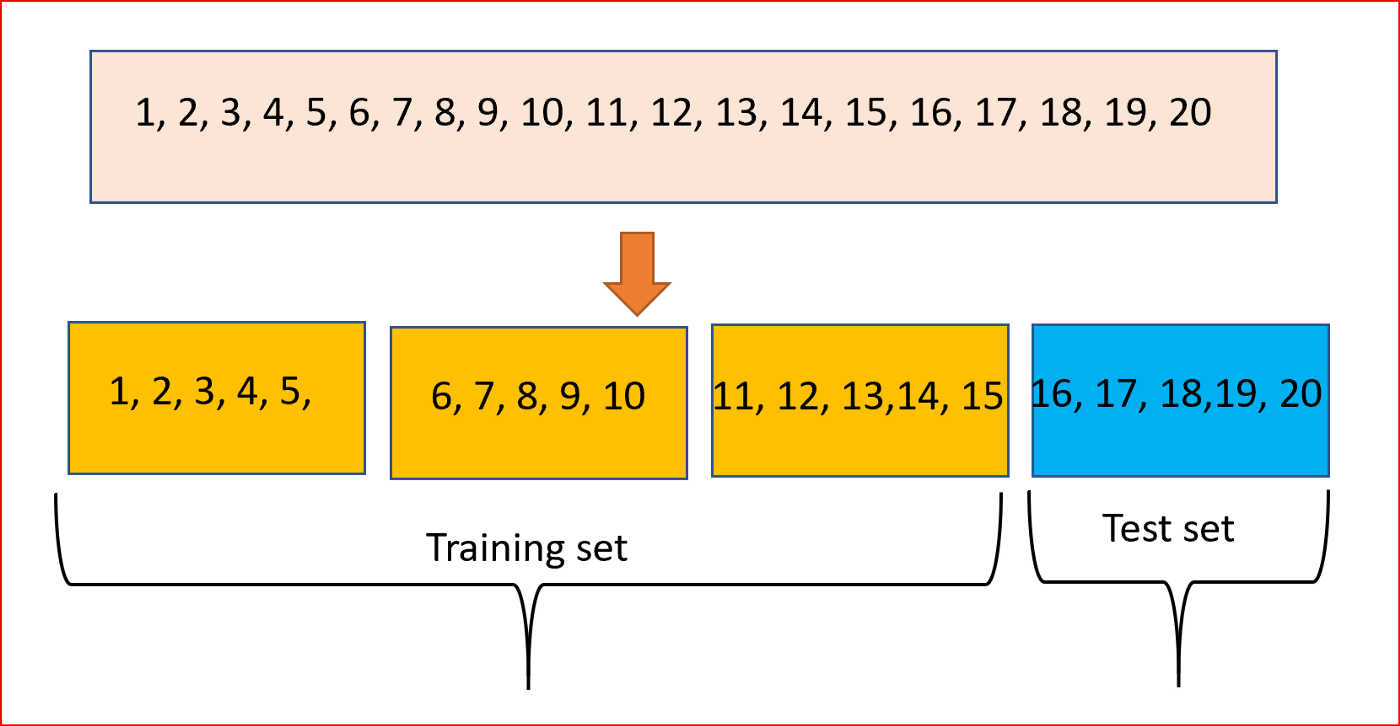
A forma como essa etapa é feita pode variar dependendo da quantidade total do conjunto de dados. Quando os dados são abundantes, utiliza-se um método chamado holdout, em que o dataset (conjunto de dados) é divididoem conjuntos de treino e teste e, às vezes, em um conjunto de validação. Caso os dados sejam limitados, a técnica utilizada para esse tipo de problema é chamada de validação cruzada (cross-validation), que começa dividindo o conjunto de dados em um número de subconjuntos de mesmo tamanho, ou aproximado.
Particionamento dos dados em 4 subconjuntos, 3 para o treino e 1 para o teste
Nas tarefas de classificação, geralmente é usada a versão estratificada desses dois métodos, que divide o conjunto de dados de forma que a proporção de cada classe nos conjuntos de treino e teste sejam aproximadamente iguais a de todo o conjunto de dados. Parece algo simples, mas os algoritmos que realizam esse procedimento o fazem de forma aleatória e não fornecem divisões balanceadas.
Além disso, essa distribuição aleatória pode levar à falta de uma classe rara (que possui poucas ocorrências) no conjunto de teste. A maneira típica como esses problemas são ignorados na literatura é através da remoção completa dessas classes. Isso, no entanto, implica que tudo bem se ignorar esse rótulo, o que raramente é verdadeiro, já que pode interferir tanto no desempenho do modelo quanto nos cálculos das métricas de avaliação.
Agora que a parte teórica foi explicada, vamos à parte prática! 🙂
Apresentação da biblioteca Scikit-multilearn
Sabia que existe uma biblioteca Python voltada apenas para problemas multi-label? Pois é, e ainda possui um nome bem sugestivo: Scikit-multilearn, tudo porque foi construída sob o conhecido ecossistema do Scikit-learn.
O Scikit-multilearn permite realizar diversas operações, mediante as implementações nativas do Python encontradas na biblioteca de métodos populares da classificação multi-label. Caso tenha curiosidade de saber tudo o que ela pode fazer, clique aqui.
A implementação da estratificação iterativa do Scikit-multilearn visa fornecer uma distribuição equilibrada das evidências das classes até uma determinada ordem. Para analisarmos o que isso significa, vamos carregar alguns dados.
Definição do problema
A competição Toxic Comment Classification do Kaggle se trata de um problema de classificação de texto, mais precisamente de classificação de comentários tóxicos. Os participantes devem criar um modelo multi-label capaz de detectar diferentes tipos de toxicidade nos comentários, como ameaças, obscenidade, insultos e ódio baseado em identidade.
Usaremos como conjunto de dados o conjunto de treino desbalanceado disponível na competição para ilustrar o problema de estratificação de dados multi-label. Esses dados contém um grande número de comentários do Wikipédia, classificados de acordo com os seguintes rótulos:
Avisamos que os comentários desse dataset podem conter texto profano, vulgar ou ofensivo, por isso algumas imagens apresentadas aqui estão borradas. O link para baixar o arquivo train.csv pode ser acessado aqui.
Análise exploratória
Inicialmente, iremos fazer uma breve análise dos dados de modo que possamos resumir as principais características do dataset. Todos os passos até a estratificação estão exemplificados abaixo, com imagens e exemplos em código Python. Se algum código estiver omitido, então alguns trechos são bastante extensos ou se tratam de funções pré-declaradas. Pedimos que acessem o código detalhado, disponível no GitHub, para um maior entendimento.
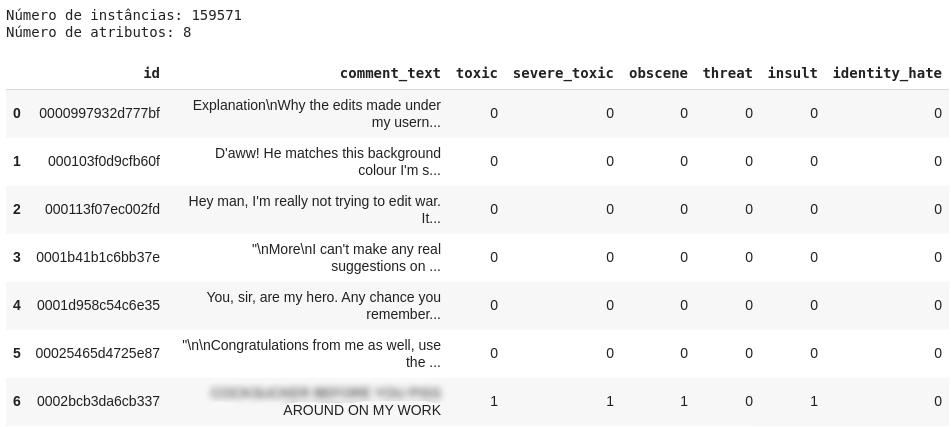
Primeiro, vamos carregar os dados do arquivo train.csv e checar os atributos.
df = pd.read_csv('train.csv')
print('Quantidade de instâncias: {}\nQuantidade de atributos: {}\n'.format(len(df), len(df.columns)))
df[0:7]
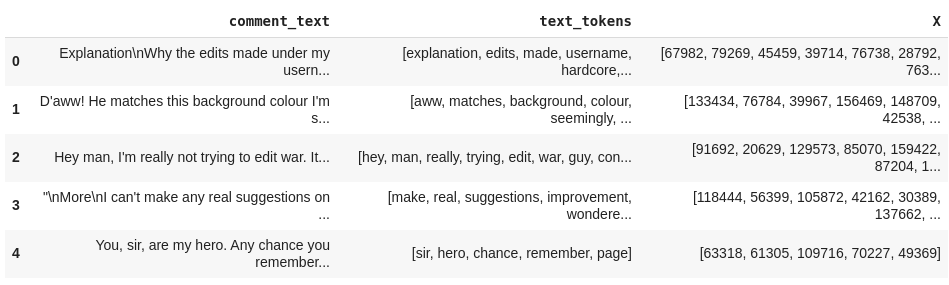
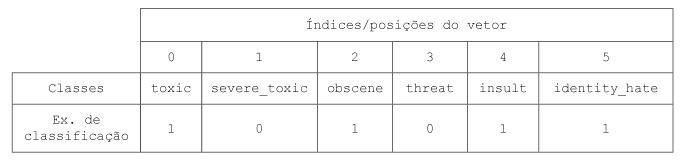
Percebe-se que cada label está representada como uma coluna, onde o valor 1 indica que o comentário possui aquela toxicidade e o valor 0 indica que não. Os 6 primeiros textos listados no dataframe não foram classificados em nenhum tipo de toxicidade. Na verdade, quase 90% desse dataset possui textos sem classificação. Não será um problema para nós, pois o método que iremos utilizar considera apenas as classificações feitas.
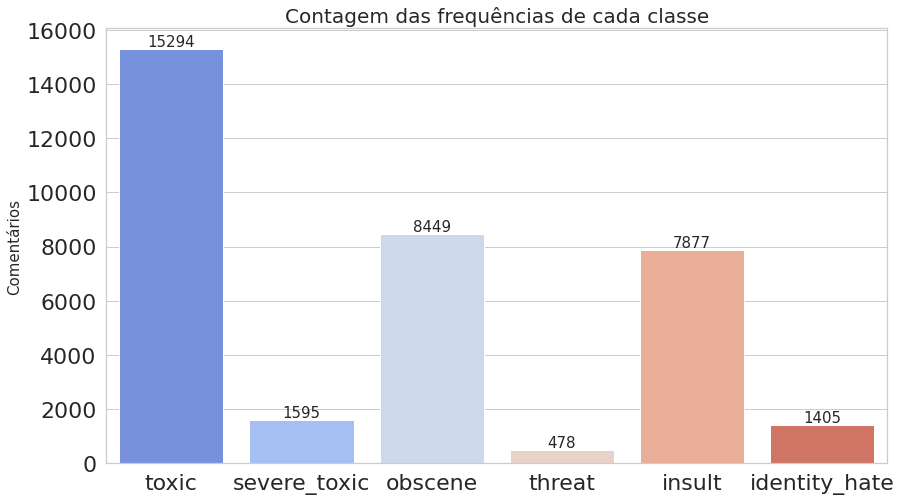
Agora, vamos computar as ocorrências de cada classe, ou seja, quantas vezes cada uma aparece, como também contar o número de comentários que foram classificados com uma ou mais classes. Já podemos notar na imagem acima do dataframe que o texto presente no índice 6 foi classificado como toxic, severe_toxic, obscene e insult.
labels = list(df.iloc[:, 2:].columns.values)
labels_count = df.iloc[:, 2:].sum().values
comments_count = df.iloc[:, 2:].sum(axis=1)
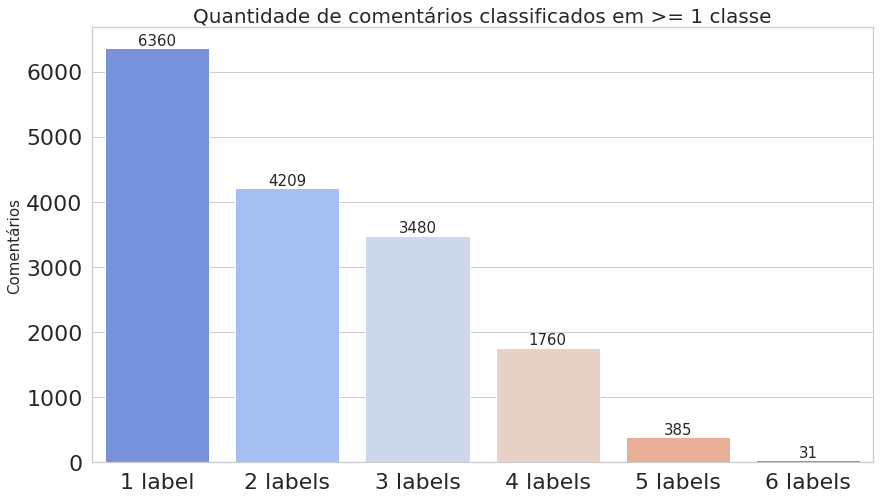
multilabel_counts = (comments_count.value_counts()).iloc[1:]
indexes = [str(i) + ' label' for i in multilabel_counts.index.sort_values()]
plot_histogram_labels(title='Contagem das frequências de cada classe', x_label=labels, y_label=labels_count, labels=labels_count)
plot_histogram_labels(title='Quantidade de comentários classificados em >= 1 classe', x_label=indexes, y_label=multilabel_counts.values, labels=multilabel_counts)
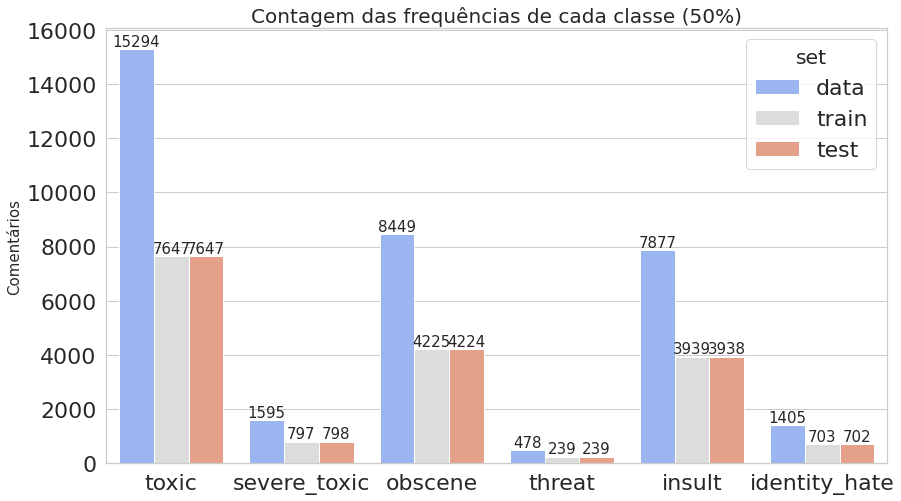
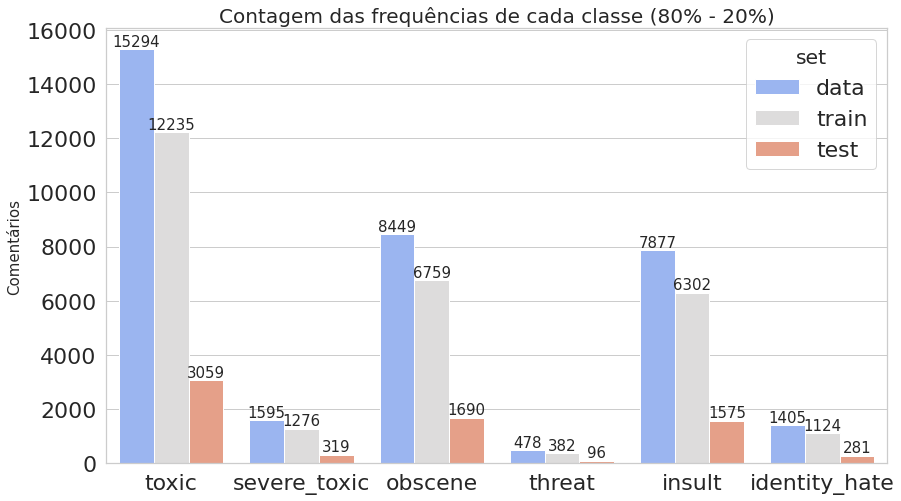
O primeiro gráfico mostra que o dataset é realmente desbalanceado, enquanto o segundo deixa claro que estamos trabalhando com dados multi-label.
Pré-processamento dos dados
O dataset não possui dados faltantes ou duplicados, e nem comentários nulos ou sem classificação (basta olhar como essa análise foi feita aqui no código completo). Apesar de não existirem problemas que podem interferir na qualidade dos dados, um pré-processamento ainda precisa ser feito, pois o intuito é seguir os mesmos passos geralmente realizados até a separação dos dados em treino e teste.
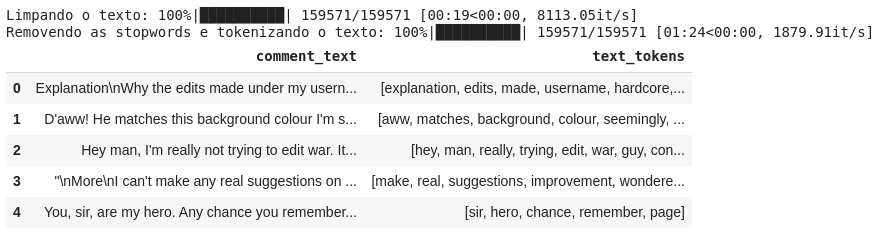
Para esse tipo de problema de classificação de texto, normalmente o pré-processamento envolve o tratamento e limpeza do texto (converter o texto apenas para letras minúsculas, remover as URLs, pontuação, números, etc.), e remoção das stopwords (conjunto de palavras comumente usadas em um determinado idioma). Devemos realizar esse tratamento para que possamos focar apenas nas palavras importantes.
tqdm.pandas(desc='Limpando o texto')
df['text_tokens'] = df['comment_text'].progress_apply(clean_text)
tqdm.pandas(desc='Removendo as stopwords e tokenizando o texto')
df['text_tokens'] = df['text_tokens'].progress_apply(remove_stopwords)
df[['comment_text', 'text_tokens']].head()
Como ilustrado na figura, também foi feito a tokenização do texto, um processo que envolve a separação de cada palavra (tokens) em blocos constituintes do texto, para depois convertê-los em vetores numéricos.
Processo de estratificação
Para divisão do conjunto de dados em conjuntos de treino e teste, usaremos o método iterative_train_test_splitda biblioteca Scikit-multilearn. Antes de prosseguir, esse método assume que possuímos as seguintes matrizes:
Devemos, então, fazer alguns tratamentos para obtermos o X e o y ideais para serem usados como entrada na função. Além disso, também passamos como parâmetro a proporção que desejamos para o teste (o restante será colocado no conjunto de treino). Esse método nos retornará a divisão estratificada do dataset(X_train, y_train, X_test, y_test).
Inicialmente, iremos gerar o X. Até agora o que temos são os tokens do texto, então precisamos mapeá-los para transformá-los em números. Para isso, podemos pegar todas as palavras (tokens) presentes em text_tokens e atribuir a cada uma um id. Assim, criaremos uma espécie de vocabulário.
text_tokens = []
VOCAB = {}
for vet in df['text_tokens'].values:
text_tokens.extend(vet)
text_tokens_set = (list(set(text_tokens)))
for index, word in enumerate(text_tokens_set):
VOCAB[word] = index + 1
print('Quantidade de palavras presentes no texto: {}'.format(len(text_tokens)))
print('Tamanho do vocabulário (palavras sem repetição): {}\n'.format(len(text_tokens_set)))
VOCAB
Com esse vocabulário, conseguimos mapear as palavras para os id’s.
Como o X deve ter a dimensão (número_de_amostras, número_de_instâncias) e como o tamanho de alguns textos deve ser bem maior que de outros, temos que achar o texto com a maior quantidade de palavras e salvar seu tamanho. Depois, fazemos um padding (preenchimento) no restante dos textos, acrescentando 0’s no final de cada vetor até atingir o tamanho máximo estabelecido.
A matriz do y deve conter a dimensão (número_de_amostras, número_de_labels), então pegamos os valores das colunas referentes às classes. Atente para o fato de que cada posição dos vetores presentes em y corresponde a uma classe.
Outra forma de criação do y seria contar as ocorrências das classes para cada texto. Logo, ao invés de utilizar valores binários para indicar que existem palavras pertencentes ou não a um rótulo, colocaríamos os valores das frequências desses rótulos.
from tensorflow.keras.preprocessing.sequence import pad_sequences
X = pad_sequences(maxlen=max_num_words, sequences=df['X'], value=0, padding='post', truncating='post')
y = df[labels].values
print('Dimensão do X: {}'.format(X.shape))
print('Dimensão do y: {}'.format(y.shape))
5. Pronto! Agora podemos fazer a divisão do dataset. Demonstraremos dois exemplos: dividir o dataset em 50% para treino e teste, e dividir em 80% para treino e 20% para teste.
from skmultilearn.model_selection import iterative_train_test_split
# 50% para cada
np.random.seed(42)
X_train, y_train, X_test, y_test = iterative_train_test_split(X, y, test_size=0.5)
# 80% para treino e 20% para teste
np.random.seed(42)
X_train_20, y_train_20, X_test_20, y_test_20 = iterative_train_test_split(X, y, test_size=0.2)
Os conjuntos de treino e teste estão realmente estratificados?
Por fim, iremos analisar se a proporção entre as classes foi realmente mantida.
Plotamos novamente os gráficos que contam quantas vezes cada classe aparece, comparando todo o conjunto de dados com os dados de treino e teste obtidos.
plot_histogram_labels('Contagem das frequências de cada classe (50%)', x_label='labels', y_label='ocorr', labels=classif_train_test, hue_label='set', data=inform_train_test)
plot_histogram_labels('Contagem das frequências de cada classe (80% - 20%)', x_label='labels', y_label='ocorr', labels=classif_train_test_20, hue_label='set', data=inform_train_test_20)
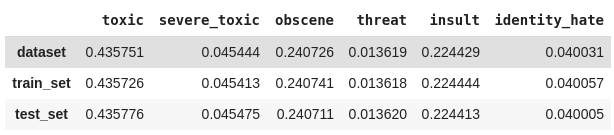
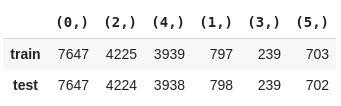
2. Podemos calcular manualmente a proporção das classes dividindo a quantidade de ocorrências de cada classe pelo número total de classificações. Também iremos verificar se a divisão está proporcional utilizando uma métricado Scikit-multilearn que retorna as combinações das classes atribuídas a cada linha.
from collections import Counter
from skmultilearn.model_selection.measures import get_combination_wise_output_matrix
pd.DataFrame({
'train': Counter(str(combination) for row in get_combination_wise_output_matrix(y_train, order=1) for combination in row),
'test' : Counter(str(combination) for row in get_combination_wise_output_matrix(y_test, order=1) for combination in row)
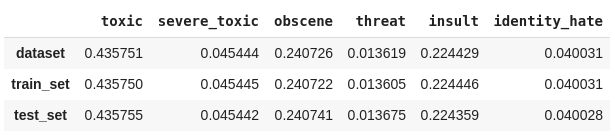
pd.DataFrame({
'train': Counter(str(combination) for row in get_combination_wise_output_matrix(y_train_20, order=1) for combination in row),
'test' : Counter(str(combination) for row in get_combination_wise_output_matrix(y_test_20, order=1) for combination in row)
}).T.fillna(0.0)
É isso, gente. Esperamos que esse post tenha sido útil, principalmente para quem já enfrentou um problema parecido e não soube o que fazer.
Nem só de álcool gel e máscara consiste o kit quarentena. Hoje, vamos aproveitar a sexta-feira + quarentena para te indicar um novo livro: Learning Geospatial Analysis with Python: Understand GIS fundamentals and perform remote sensing data analysis using Python 3.7.
Dos dez capítulos, o autor, Joel Lawhead, dedica os três primeiros à ambientação dos leitores no cenário da Análise Geoespacial. Para a estruturação de desenvolvimento do tema, divide o campo em suas áreas específicas, como Sistema de Informações Geográficas (SIG), sensoriamento remoto, dados de elevação, modelagem avançada e dados em tempo real. A partir do capítulo 4, o autor inicia o aprofundamento da parte computacional, introduzindo o uso de ferramentas como NumPy, GEOS, Shapely e Python Imaging Library.
O foco do livro é fornecer uma “base sólida no uso da poderosa linguagem e estrutura Python para abordar a análise geoespacial de maneira eficaz”, como afirma o próprio autor. Para isso, Lawhead privilegia a aplicação do tema, sempre que possível, no ambiente Python. O esforço para se concentrar no Python, sem dependências, é um dos grandes diferenciais de “Learning Geospatial Analysis with Python” em relação aos outros materiais disponíveis sobre o assunto.
Veja a divisão do livro por capítulos:
1- Aprendendo sobre Análise Geoespacial com Python.
2- Aprendendo dados geoespaciais.
3- O cenário da tecnologia geoespacial.
4- Python Toolbox Geoespacial.
5- Sistema de Informações Geográficas e Python.
6- Python e Sensoriamento Remoto.
7- Python e Dados de Elevação.
8- Modelagem Geoespacial Avançada de Python.
9- Dados em tempo real.
10- Juntando tudo.
Conheça o autor*:
Joel Lawhead é um profissional de gerenciamento de projetos certificado pelo PMI, um profissional de GIS certificado e o diretor de informações da NVision Solutions Inc., uma empresa premiada especializada em integração de tecnologia geoespacial e engenharia de sensores para NASA, FEMA, NOAA, Marinha dos EUA , e muitas outras organizações comerciais e sem fins lucrativos.
*Trecho extraído de amazon.com.
Aproveita que está aqui com a gente e leia também:
12 bibliotecas do Python para análise de dados espaço-temporais (Parte 1) – (Parte 2)
Nós usamos cookies para melhorar sua experiência de navegação. Ao navegar no site, você concorda com a política de monitoramento de cookies. Se você concorda, clique em OK. Para ter mais informações sobre como isso é feito, acesse nosso Aviso de Privacidade.OKAviso de Privacidade